

التفوق على التدريب الكامل باستخدام 0.2% فقط من المعلمات
جدول الروابط
نبذة مختصرة و1. مقدمة
-
الخلفية
2.1 مزيج من الخبراء
2.2 المحولات
-
مزيج من التكيفات
3.1 سياسة التوجيه
3.2 تنظيم الاتساق
3.3 دمج وحدة التكيف و 3.4 مشاركة وحدة التكيف
3.5 الاتصال بالشبكات العصبية البايزية ونماذج التجميع
-
التجارب
4.1 إعداد التجارب
4.2 النتائج الرئيسية
4.3 دراسة الاستئصال
-
الأعمال ذات الصلة
-
الاستنتاجات
-
القيود
-
شكر وتقدير والمراجع
الملحق
أ. مجموعات بيانات NLU قليلة اللقطات ب. دراسة الاستئصال ج. نتائج مفصلة حول مهام NLU د. المعلمات الفائقة
5 الأعمال ذات الصلة
الضبط الدقيق الفعال للمعلمات لنماذج اللغة المسبقة التدريب. يمكن تصنيف الأعمال الحديثة حول الضبط الدقيق الفعال للمعلمات (PEFT) بشكل تقريبي إلى فئتين
\ 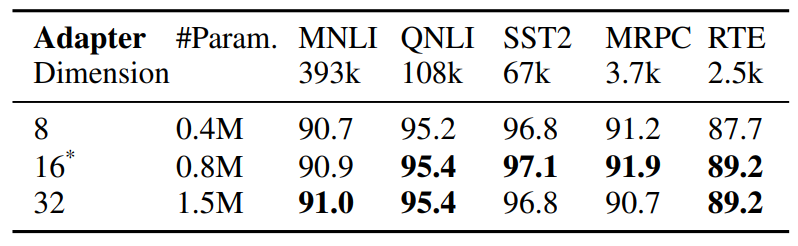
\ الفئات: (1) ضبط مجموعة فرعية من المعلمات الموجودة بما في ذلك الضبط الدقيق للرأس (Lee et al., 2019)، وضبط مصطلح التحيز (Zaken et al., 2021)، (2) ضبط المعلمات المقدمة حديثًا بما في ذلك المحولات (Houlsby et al., 2019; Pfeiffer et al., 2020)، وضبط المطالبة (Lester et al., 2021)، وضبط البادئة (Li and Liang, 2021) والتكيف منخفض الرتبة (Hu et al., 2021). على عكس الأعمال السابقة التي تعمل على وحدة تكيف واحدة، يقدم AdaMix مزيجًا من وحدات التكيف مع التوجيه العشوائي أثناء التدريب ودمج وحدة التكيف أثناء الاستدلال للحفاظ على نفس التكلفة الحسابية كما هو الحال مع وحدة واحدة. علاوة على ذلك، يمكن استخدام AdaMix فوق أي طريقة PEFT لتعزيز أدائها بشكل أكبر.
\ مزيج من الخبراء (MoE). قدم Shazeer et al., 2017 نموذج MoE مع شبكة بوابة واحدة مع توجيه T op-k وموازنة الحمل عبر الخبراء. يقترح Fedus et al., 2021 مخططات التهيئة والتدريب لتوجيه T op-1. يقترح Zuo et al., 2021 تنظيم الاتساق للتوجيه العشوائي؛ يقترح Yang et al., 2021 توجيه k T op-1 مع نماذج أولية للخبراء، ويعالج Roller et al., 2021; Lewis et al., 2021 مشكلات موازنة الحمل الأخرى. تدرس جميع الأعمال المذكورة أعلاه MoE المتناثر مع تدريب النموذج بأكمله من الصفر. في المقابل، ندرس التكيف الفعال للمعلمات لنماذج اللغة المدربة مسبقًا من خلال ضبط عدد صغير جدًا من معلمات المحول المتناثرة.
\ متوسط أوزان النموذج. تدرس الاستكشافات الحديثة (Szegedy et al., 2016; Matena and Raffel, 2021; Wortsman et al., 2022; Izmailov et al., 2018) تجميع النماذج من خلال حساب متوسط جميع أوزان النموذج. يقترح (Matena and Raffel, 2021) دمج نماذج اللغة المدربة مسبقًا والتي تم ضبطها بدقة على مهام تصنيف النصوص المختلفة. يستكشف (Wortsman et al., 2022) حساب متوسط أوزان النموذج من عمليات تشغيل مستقلة مختلفة على نفس المهمة باستخدام تكوينات معلمات فائقة مختلفة. على عكس الأعمال المذكورة أعلاه حول الضبط الدقيق للنموذج الكامل، نركز على الضبط الدقيق الفعال للمعلمات. نستكشف متوسط الوزن لدمج أوزان وحدات التكيف التي تتكون من معلمات قابلة للضبط صغيرة يتم تحديثها أثناء ضبط النموذج مع الحفاظ على ثبات معلمات النموذج الكبيرة.
6 الاستنتاجات
قمنا بتطوير إطار عمل جديد AdaMix للضبط الدقيق الفعال للمعلمات (PEFT) لنماذج اللغة الكبيرة المدربة مسبقًا (PLM). يستفيد AdaMix من مزيج من وحدات التكيف لتحسين أداء المهام اللاحقة دون زيادة التكلفة الحسابية (مثل FLOPs، المعلمات) لطريقة التكيف الأساسية. نوضح أن AdaMix يعمل مع ويتفوق على طرق PEFT المختلفة مثل المحولات والتحليلات منخفضة الرتبة عبر مهام NLU و NLG.
\ من خلال ضبط 0.1 - 0.2٪ فقط من معلمات PLM، يتفوق AdaMix على الضبط الدقيق للنموذج الكامل الذي يحدث جميع معلمات النموذج وكذلك طرق PEFT الأخرى المتطورة.
7 القيود
طريقة AdaMix المقترحة تتطلب حوسبة مكثفة إلى حد ما لأنها تتضمن الضبط الدقيق لنماذج اللغة واسعة النطاق. تكلفة تدريب AdaMix المقترحة أعلى من طرق PEFT القياسية لأن إجراء التدريب يتضمن نسخًا متعددة من المحولات. بناءً على ملاحظتنا التجريبية، فإن عدد تكرارات التدريب لـ AdaMix عادة ما يكون بين 1~2 مرة من التدريب لطرق PEFT القياسية. هذا يفرض تأثيرًا سلبيًا على البصمة الكربونية من تدريب النماذج الموصوفة.
\ AdaMix متعامد مع معظم دراسات الضبط الدقيق الفعال للمعلمات (PEFT) الموجودة وقادر على تحسين أداء أي طريقة PEFT بشكل محتمل. في هذا العمل، نستكشف طريقتين تمثيليتين لـ PEFT مثل المحول و LoRA لكننا لم نجرب مع مجموعات أخرى مثل ضبط المطالبة وضبط البادئة. نترك تلك الدراسات للعمل المستقبلي.
8 شكر وتقدير
يود المؤلفون أن يشكروا المحكمين المجهولين على تعليقاتهم القيمة واقتراحاتهم المفيدة ويودون أن يشكروا Guoqing Zheng و Ruya Kang على تعليقاتهم البصيرة على المشروع. هذا العمل مدعوم جزئيًا من قبل مؤسسة العلوم الوطنية الأمريكية بموجب منح NSFIIS 1747614 و NSF-IIS-2141037. أي آراء أو نتائج أو استنتاجات أو توصيات واردة في هذه المادة هي آراء المؤلف (المؤلفين) ولا تعكس بالضرورة وجهات نظر مؤسسة العلوم الوطنية.
المراجع
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. 2021. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 7319– 7328, Online. Association for Computational Linguistics.
\ Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 2006. The second PASCAL recognising textual entailment challenge.
\ Luisa Bentivogli, Peter Clark, Ido Dagan, and Danilo Giampiccolo. 2009. The fifth PASCAL recognizing textual entailment challenge. In TAC.
\ Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel HerbertVoss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
\ Ido Dagan, Oren Glickman, and Bernardo Magnini. 2005. The PASCAL recognising textual entailment challenge. In the First International Conference on Machine Learning Challenges: Evaluating Predictive Uncertainty Visual Object Classification, and Recognizing Textual Entailment.
\ Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers), pages 4171–4186.
\ William Fedus, Barret Zoph, and Noam Shazeer. 2021. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv preprint arXiv:2101.03961.
\ Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. 2020. Linear mode connectivity and the lottery ticket hypothesis. In International Conference on Machine Learning, pages 3259–3269. PMLR.
\ Yarin Gal and Zoubin Ghahramani. 2015. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. CoRR, abs/1506.02142.
\ Yarin Gal, Riashat Islam, and Zoubin Ghahram
قد يعجبك أيضاً

استخدم XRP لتنشيط عقود تعدين بيتكوين (BTC) عن بُعد واربح أكثر من 10,000 دولار يومياً.

ما الذي يدفع تقييم Avalanche إلى 675 مليون دولار؟
