

حل ندرة البيانات: S-CycleGAN للترجمة من الأشعة المقطعية إلى الموجات فوق الصوتية
جدول الروابط
نبذة مختصرة و 1 مقدمة
-
الأعمال ذات الصلة
-
إعداد المشكلة
-
المنهجية
4.1. التقطير المدرك لحدود القرار
4.2. توحيد المعرفة
-
النتائج التجريبية و 5.1. إعداد التجربة
5.2. المقارنة مع طرق SOTA
5.3. دراسة الاستئصال
-
الخاتمة والعمل المستقبلي والمراجع
\
المواد التكميلية
- تفاصيل التحليل النظري لآلية KCEMA في IIL
- نظرة عامة على الخوارزمية
- تفاصيل مجموعة البيانات
- تفاصيل التنفيذ
- تصور الصور المدخلة المغبرة
- المزيد من النتائج التجريبية
نبذة مختصرة
يركز التعلم التزايدي للحالات (IIL) على التعلم المستمر باستخدام بيانات من نفس الفئات. مقارنة بالتعلم التزايدي للفئات (CIL)، نادراً ما يتم استكشاف IIL لأنه يعاني أقل من النسيان الكارثي (CF). ومع ذلك، إلى جانب الاحتفاظ بالمعرفة، في سيناريوهات النشر في العالم الحقيقي حيث يكون فضاء الفئات محدداً مسبقاً، فإن الترويج المستمر والفعال من حيث التكلفة للنموذج مع عدم توفر البيانات السابقة المحتمل هو مطلب أكثر أهمية. لذلك، نحدد أولاً إعداداً جديداً وأكثر عملية لـ IIL كـ تعزيز أداء النموذج إلى جانب مقاومة CF باستخدام الملاحظات الجديدة فقط. يجب معالجة مشكلتين في إعداد IIL الجديد: 1) النسيان الكارثي سيئ السمعة بسبب عدم الوصول إلى البيانات القديمة، و 2) توسيع حدود القرار الحالية للملاحظات الجديدة بسبب انحراف المفهوم. لمعالجة هذه المشاكل، تتمثل رؤيتنا الرئيسية في توسيع حدود القرار باعتدال لحالات الفشل مع الاحتفاظ بالحدود القديمة. وبالتالي، نقترح طريقة تقطير جديدة مدركة لحدود القرار مع توحيد المعرفة للمعلم لتسهيل تعلم الطالب للمعرفة الجديدة. كما أننا نضع المعايير على مجموعات البيانات الموجودة Cifar-100 و ImageNet. ومن الجدير بالذكر أن التجارب المكثفة تظهر أن نموذج المعلم يمكن أن يكون متعلماً تزايدياً أفضل من نموذج الطالب، مما يقلب الطرق السابقة المعتمدة على تقطير المعرفة التي تعامل الطالب كدور رئيسي.
1. مقدمة
في السنوات الأخيرة، تم اقتراح العديد من الشبكات الممتازة القائمة على التعلم العميق لمجموعة متنوعة من المهام، مثل تصنيف الصور والتجزئة والكشف. على الرغم من أن هذه الشبكات تعمل بشكل جيد على بيانات التدريب، إلا أنها تفشل حتماً في بعض البيانات الجديدة التي لم يتم تدريبها في التطبيق العملي. إن تعزيز أداء النموذج المنشور باستمرار وكفاءة على هذه البيانات الجديدة هو مطلب أساسي. الحل الحالي المتمثل في إعادة تدريب الشبكة باستخدام جميع البيانات المتراكمة له عيبان: 1) مع زيادة حجم البيانات، تزداد تكلفة التدريب في كل مرة، على سبيل المثال، المزيد من ساعات وحدات معالجة الرسومات وبصمة كربونية أكبر [20]، و 2) في بعض الحالات لم تعد البيانات القديمة متاحة بسبب سياسة الخصوصية أو الميزانية المحدودة لتخزين البيانات. في الحالة التي تكون فيها البيانات القديمة متاحة بشكل قليل أو غير متاحة أو مستخدمة، فإن إعادة تدريب نموذج التعلم العميق باستخدام بيانات جديدة تسبب دائماً تدهور الأداء على البيانات القديمة، أي مشكلة النسيان الكارثي (CF). لمعالجة مشكلة CF، تم اقتراح التعلم التزايدي [4، 5، 22، 29]، المعروف أيضاً باسم التعلم المستمر. يعزز التعلم التزايدي بشكل كبير القيمة العملية لنماذج التعلم العميق ويجذب اهتمامات بحثية مكثفة.
\ 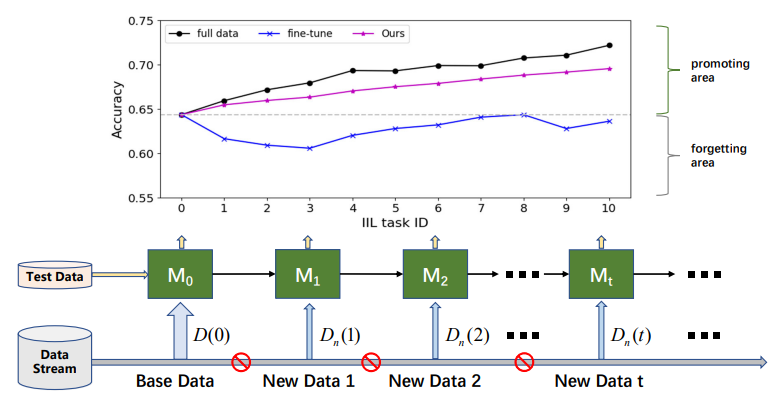
\ وفقاً لما إذا كانت البيانات الجديدة تأتي من فئات مرئية، يمكن تقسيم التعلم التزايدي إلى ثلاثة سيناريوهات [16، 17]: التعلم التزايدي للحالات (IIL) [3، 16] حيث تنتمي جميع البيانات الجديدة إلى الفئات المرئية، والتعلم التزايدي للفئات (CIL) [4، 12، 15، 22] حيث تحتوي البيانات الجديدة على تسميات فئات مختلفة، والتعلم التزايدي الهجين [6، 30] حيث تتكون البيانات الجديدة من ملاحظات جديدة من الفئات القديمة والجديدة. مقارنة بـ CIL، فإن IIL غير مستكشف نسبياً لأنه أقل عرضة للـ CF. أفاد Lomonaco و Maltoni [16] أن الضبط الدقيق للنموذج مع الإيقاف المبكر يمكن أن يروض مشكلة CF بشكل جيد في IIL. ومع ذلك، فإن هذا الاستنتاج لا يصمد دائماً عندما لا يكون هناك وصول إلى بيانات التدريب القديمة وتكون البيانات الجديدة ذات حجم أصغر بكثير من البيانات القديمة، كما هو موضح في الشكل 1. غالباً ما يؤدي الضبط الدقيق إلى تحول في حدود القرار بدلاً من توسيعها لاستيعاب الملاحظات الجديدة. إلى جانب الاحتفاظ بالمعرفة القديمة، يهتم النشر الحقيقي أكثر بتعزيز النموذج بكفاءة في IIL. على سبيل المثال، في الكشف عن عيوب المنتجات الصناعية، تكون فئات العيوب دائماً محدودة بفئات معروفة. لكن مورفولوجيا تلك العيوب تختلف من وقت لآخر. يجب تصحيح الإخفاقات في تلك العيوب غير المرئية في الوقت المناسب وبكفاءة لتجنب تدفق المنتجات المعيبة إلى السوق. للأسف، تركز الأبحاث الحالية بشكل أساسي على الاحتفاظ بالمعرفة حول البيانات القديمة بدلاً من إثراء المعرفة بالملاحظات الجديدة.
\ في هذه الورقة، لتعزيز نموذج مدرب بسرعة وفعالية من حيث التكلفة مع ملاحظات جديدة من الفئات المرئية، نحدد أولاً إعداداً جديداً لـ IIL كـ الاحتفاظ بالمعرفة المكتسبة وكذلك تعزيز أداء النموذج على الملاحظات الجديدة دون الوصول إلى البيانات القديمة. بكلمات بسيطة، نهدف إلى تعزيز النموذج الحالي من خلال الاستفادة من البيانات الجديدة فقط وتحقيق أداء مماثل للنموذج المعاد تدريبه مع جميع البيانات المتراكمة. يعد IIL الجديد تحدياً بسبب انحراف المفهوم [6] الناجم عن الملاحظات الجديدة، مثل تغير اللون أو الشكل مقارنة بالبيانات القديمة. وبالتالي، يجب معالجة مشكلتين في إعداد IIL الجديد: 1) النسيان الكارثي سيئ السمعة بسبب عدم الوصول إلى البيانات القديمة، و 2) توسيع حدود القرار الحالية للملاحظات الجديدة.
\ لمعالجة المشكلات المذكورة أعلاه في إعداد IIL الجديد، نقترح إطار عمل IIL جديداً يعتمد على هيكل المعلم والطالب. يتكون الإطار المقترح من عملية تقطير مدركة لحدود القرار (DBD) وعملية توحيد المعرفة (KC). يسمح DBD لنموذج الطالب بالتعلم من الملاحظات الجديدة مع الوعي بحدود القرار بين الفئات الموجودة، مما يمكّن النموذج من تحديد أين يعزز معرفته وأين يحتفظ بها. ومع ذلك، فإن حدود القرار لا يمكن تتبعها عندما لا توجد عينات كافية موجودة حول الحدود بسبب عدم الوصول إلى البيانات القديمة في IIL. للتغلب على ذلك، نستلهم من ممارسة تغبير الأرضية بالدقيق للكشف عن آثار الأقدام المخفية. وبالمثل، نقدم ضوضاء جاوسية عشوائية لتلويث مساحة الإدخال وإظهار حدود القرار المتعلمة للتقطير. أثناء تدريب نموذج الطالب مع تقطير الحدود، يتم توحيد المعرفة المحدثة مرة أخرى إلى نموذج المعلم بشكل متقطع ومتكرر مع آلية EMA [28]. استخدام نموذج المعلم كنموذج مستهدف هو
قد يعجبك أيضاً

خبراء البيتكوين يتحدثون بصراحة: سايلور وكيوساكي يقدمان توقعاتهما للعام

هيديرا تحصل على أول صندوق ETF لها: صندوق HBAR من كاناري يتيح للمستثمرين الاستفادة من طفرة الترميز
