

كيف يجعل مزيج التكيفات ضبط نموذج اللغة أرخص وأذكى
جدول الروابط
نبذة مختصرة و1. مقدمة
-
الخلفية
2.1 مزيج من الخبراء
2.2 المحولات
-
مزيج من التكيفات
3.1 سياسة التوجيه
3.2 تنظيم الاتساق
3.3 دمج وحدة التكيف و 3.4 مشاركة وحدة التكيف
3.5 الاتصال بالشبكات العصبية البايزية وتجميع النماذج
-
التجارب
4.1 إعداد التجارب
4.2 النتائج الرئيسية
4.3 دراسة الاستئصال
-
الأعمال ذات الصلة
-
الاستنتاجات
-
القيود
-
شكر وتقدير والمراجع
الملحق
أ. مجموعات بيانات NLU قليلة اللقطات ب. دراسة الاستئصال ج. نتائج مفصلة حول مهام NLU د. المعلمات الفائقة
3 مزيج من التكيفات

\
3.1 سياسة التوجيه
أظهرت الأعمال الحديثة مثل THOR (Zuo et al., 2021) أن سياسة التوجيه العشوائية مثل التوجيه العشوائي تعمل بشكل جيد مثل آلية التوجيه الكلاسيكية مثل توجيه التبديل (Fedus et al., 2021) مع الفوائد التالية. نظرًا لأن أمثلة الإدخال يتم توجيهها عشوائيًا إلى خبراء مختلفين، فلا توجد حاجة لموازنة إضافية للحمل حيث يتمتع كل خبير بفرصة متساوية للتنشيط مما يبسط الإطار. علاوة على ذلك، لا توجد معلمات مضافة، وبالتالي لا توجد حسابات إضافية، في طبقة التبديل لاختيار الخبير. الأخير مهم بشكل خاص في إعدادنا للضبط الدقيق الفعال للمعلمات للحفاظ على المعلمات وعمليات FLOPs كما هو الحال في وحدة تكيف واحدة. لتحليل عمل AdaMix، نوضح الاتصالات بالتوجيه العشوائي ومتوسط وزن النموذج إلى الشبكات العصبية البايزية وتجميع النماذج في القسم 3.5.
\ \ 
\ \ يتيح هذا التوجيه العشوائي لوحدات التكيف تعلم تحويلات مختلفة أثناء التدريب والحصول على وجهات نظر متعددة للمهمة. ومع ذلك، فإن هذا يخلق أيضًا تحديًا حول الوحدات التي يجب استخدامها أثناء الاستدلال بسبب بروتوكول التوجيه العشوائي أثناء التدريب. نعالج هذا التحدي باستخدام التقنيتين التاليتين اللتين تسمحان لنا أيضًا بطي وحدات التكيف والحصول على نفس التكلفة الحسابية (FLOPs، معلمات التكيف القابلة للضبط) كما هو الحال في وحدة واحدة.
3.2 تنظيم الاتساق
\ 
\ \ \ 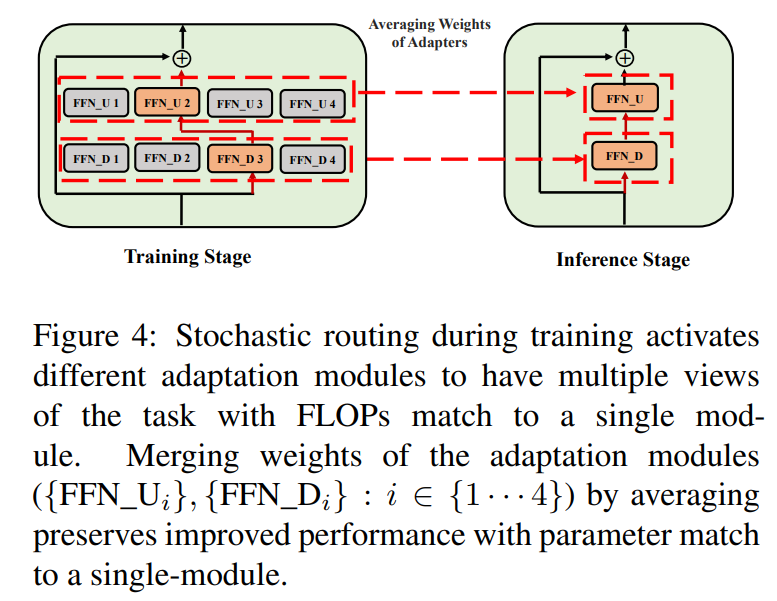
3.3 دمج وحدة التكيف
في حين أن التنظيم المذكور أعلاه يخفف من عدم الاتساق في اختيار الوحدة العشوائية أثناء الاستدلال، إلا أنه لا يزال يؤدي إلى زيادة تكلفة الخدمة لاستضافة العديد من وحدات التكيف. أظهرت الأعمال السابقة في الضبط الدقيق لنماذج اللغة للمهام اللاحقة أداءً محسنًا عند متوسط أوزان النماذج المختلفة المضبوطة بدقة مع بذور عشوائية مختلفة تتفوق على نموذج واحد مضبوط بدقة. أظهرت الأعمال الحديثة (Wortsman et al., 2022) أيضًا أن النماذج المضبوطة بشكل مختلف من نفس التهيئة تقع في نفس حوض الخطأ مما يحفز استخدام تجميع الوزن لتلخيص المهام القوية. نتبنى ونوسع التقنيات السابقة للضبط الدقيق لنموذج اللغة لتدريبنا الفعال للمعلمات لوحدات التكيف متعددة الرؤى
\ \ 
\
3.4 مشاركة وحدة التكيف
\ 
3.5 الاتصال بالشبكات العصبية البايزية وتجميع النماذج
\ 
\ \ يتطلب هذا المتوسط على جميع أوزان النموذج الممكنة، وهو أمر غير قابل للتطبيق عمليًا. لذلك، تم تطوير العديد من طرق التقريب بناءً على طرق الاستدلال المتغيرة وتقنيات التنظيم العشوائي باستخدام عمليات التسريب. في هذا العمل، نستفيد من تنظيم عشوائي آخر في شكل توجيه عشوائي. هنا، الهدف هو العثور على توزيع بديل qθ(w) في عائلة قابلة للتطبيق من التوزيعات التي يمكن أن تحل محل النموذج الخلفي الحقيقي الذي يصعب حسابه. يتم تحديد البديل المثالي عن طريق تقليل تباعد كولباك-ليبلر (KL) بين المرشح والخلفية الحقيقية.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info المؤلفون:
(1) ياكينغ وانغ، جامعة بوردو (wang5075@purdue.edu);
(2) ساهاج أغاروال، مايكروسوفت (sahagar@microsoft.com);
(3) سوبهابراتا موخيرجي، أبحاث مايكروسوفت (submukhe@microsoft.com);
(4) شياودونغ ليو، أبحاث مايكروسوفت (xiaodl@microsoft.com);
(5) جينغ غاو، جامعة بوردو (jinggao@purdue.edu);
(6) أحمد حسن عوض الله، أبحاث مايكروسوفت (hassanam@microsoft.com);
(7) جيانفينغ غاو، أبحاث مايكروسوفت (jfgao@microsoft.com).
:::
:::info هذه الورقة متاحة على arxiv تحت رخصة CC BY 4.0 DEED.
:::
\
قد يعجبك أيضاً

ميتابلانيت تضيف 25,555 بيتكوين مع ارتفاع البيتكوين إلى 116,000 دولار

ناسداك تقدم طلباً إلى هيئة الأوراق المالية والبورصات لإدراج صندوق بلاك روك بيتكوين للدخل المميز المتداول في البورصة
