

إعداد IIL الجديد: تعزيز النماذج المنشورة باستخدام البيانات الجديدة فقط
جدول الروابط
نبذة مختصرة و1 مقدمة
-
الأعمال ذات الصلة
-
إعداد المشكلة
-
المنهجية
4.1. التقطير المدرك لحدود القرار
4.2. توحيد المعرفة
-
النتائج التجريبية و5.1. إعداد التجربة
5.2. المقارنة مع طرق SOTA
5.3. دراسة الاستئصال
-
الخلاصة والعمل المستقبلي والمراجع
\
المواد التكميلية
- تفاصيل التحليل النظري لآلية KCEMA في IIL
- نظرة عامة على الخوارزمية
- تفاصيل مجموعة البيانات
- تفاصيل التنفيذ
- تصور للصور المدخلة المغبرة
- المزيد من النتائج التجريبية
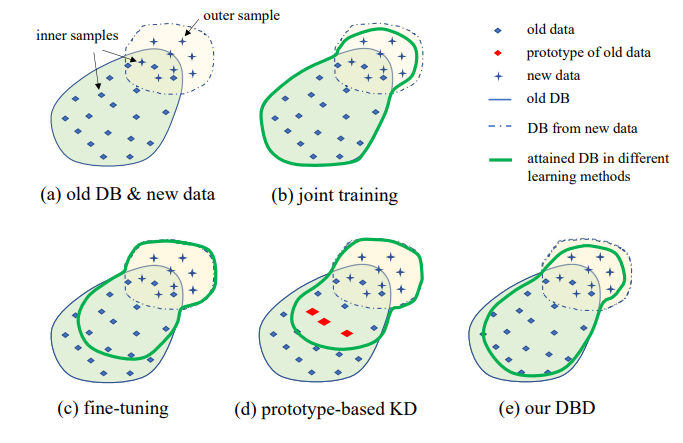
3. إعداد المشكلة
يظهر توضيح إعداد IIL المقترح في الشكل 1. كما يمكن رؤيته، يتم إنشاء البيانات باستمرار وبشكل غير متوقع في تدفق البيانات. بشكل عام في التطبيق الواقعي، يميل الناس إلى جمع بيانات كافية أولاً وتدريب نموذج قوي M0 للنشر. بغض النظر عن مدى قوة النموذج، فإنه سيواجه حتماً بيانات خارج التوزيع وسيفشل فيها. سيتم تعليم هذه الحالات الفاشلة وغيرها من الملاحظات الجديدة ذات الدرجات المنخفضة لتدريب النموذج من وقت لآخر. إعادة تدريب النموذج بجميع البيانات المتراكمة في كل مرة يؤدي إلى تكلفة أعلى وأعلى في الوقت والموارد. لذلك، يهدف IIL الجديد إلى تعزيز النموذج الحالي باستخدام البيانات الجديدة فقط في كل مرة.
\ 
\ 
\
:::info المؤلفون:
(1) تشيانغ ني، جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو)؛
(2) ويفو فو، مختبر تينسنت يوتو؛
(3) يوهوان لين، مختبر تينسنت يوتو؛
(4) جيالين لي، مختبر تينسنت يوتو؛
(5) ييفنغ تشو، مختبر تينسنت يوتو؛
(6) يونغ ليو، مختبر تينسنت يوتو؛
(7) تشيانغ ني، جامعة هونغ كونغ للعلوم والتكنولوجيا (قوانغتشو)؛
(8) تشنغجي وانغ، مختبر تينسنت يوتو.
:::
:::info هذه الورقة متاحة على arxiv تحت رخصة CC BY-NC-ND 4.0 Deed (النسب-غير تجاري-عدم الاشتقاق 4.0 الدولية).
:::
\
قد يعجبك أيضاً

إضافة ريديت وكيك إلى القائمة السوداء المتنامية لوسائل التواصل الاجتماعي للمراهقين في أستراليا

هذه العملات البديلة تحقق أرباحاً بينما يتراجع السوق: إليك المشاريع التي تحقق أكبر قدر من الإيرادات
