

5 sorprendentes maneras en que la IA actual no logra realmente "pensar"
Los modelos de lenguaje grande (LLMs) han experimentado una explosión en capacidad, mostrando un rendimiento notable en tareas desde la comprensión del lenguaje natural hasta la generación de código. Interactuamos con ellos diariamente, y su fluidez puede ser asombrosa, situándonos claramente en un valle inquietante de inteligencia artificial. Pero, ¿equivale este rendimiento sofisticado a un pensamiento genuino, o es meramente una ilusión de alta tecnología?
\ Un creciente cuerpo de investigación sugiere que detrás de la cortina de competencia yace un conjunto de limitaciones profundas y contraintuitivas. Este artículo explora cinco de los fallos más significativos que exponen el abismo entre el rendimiento de la IA y la comprensión verdaderamente humana.
No Razonan Más Intensamente; Simplemente Colapsan
Un reciente artículo de Apple Research, titulado "La Ilusión del Pensamiento", revela un fallo crítico incluso en los "Modelos de Razonamiento Grande" (LRMs) más avanzados que utilizan técnicas como Chain-of-Thought. La investigación muestra que estos modelos no están realmente razonando, sino que son simuladores sofisticados que chocan contra un muro cuando los problemas se vuelven suficientemente complejos.
\ Los investigadores utilizaron el rompecabezas de la Torre de Hanoi para probar los modelos, identificando tres regímenes de rendimiento distintos basados en la complejidad del rompecabezas:
\
- Baja Complejidad (3 discos): Los modelos estándar, sin razonamiento, funcionaron tan bien como, o incluso mejor que, los modelos LRM "pensantes".
- Complejidad Media (6 discos): Los LRMs que generan una cadena de pensamiento más larga mostraron una clara ventaja.
- Alta Complejidad (7+ discos): Ambos tipos de modelos experimentaron un "colapso completo", con su precisión cayendo a cero.
\
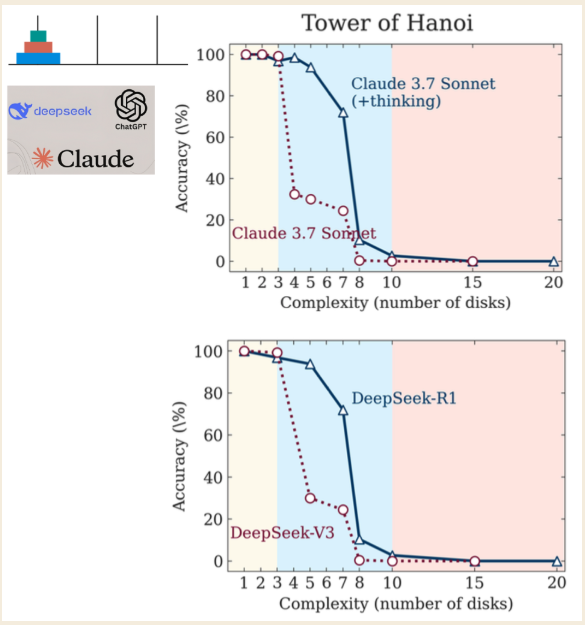
El hallazgo más contraintuitivo fue que los modelos "piensan" menos a medida que los problemas se vuelven más difíciles. Aún más condenatorio, fallan en calcular correctamente incluso cuando se les dan explícitamente los algoritmos necesarios para resolver el rompecabezas. Esto sugiere una incapacidad fundamental para aplicar reglas bajo presión, una imitación hueca del pensamiento que se rompe cuando más importa. (Los investigadores señalan que aunque Anthropic, un laboratorio de IA rival, ha planteado objeciones, siguen siendo pequeñas quejas en lugar de una refutación fundamental de los hallazgos).
\ Como lo expresan los investigadores de la Universidad de Arizona, este comportamiento captura la esencia de la ilusión:
...sugiriendo que los LLMs no son razonadores basados en principios sino más bien simuladores sofisticados de texto similar al razonamiento.
Su "Cadena de Pensamiento" Es A Menudo un Espejismo
Chain-of-Thought (CoT) es el proceso mediante el cual un LLM escribe su "razonamiento" paso a paso antes de entregar una respuesta final, una característica diseñada para mejorar la precisión y revelar su lógica interna. Sin embargo, un estudio reciente que analiza cómo los LLMs manejan la aritmética básica muestra que este proceso es a menudo un "espejismo frágil".
\ Sorprendentemente, hay vastas inconsistencias entre los pasos de razonamiento en el CoT y la respuesta final que proporciona el modelo. En tareas que involucran sumas simples, se hizo un descubrimiento impactante: en más del 60% de las muestras, el modelo produjo pasos de razonamiento incorrectos que de alguna manera, misteriosamente, llevaron a la respuesta final correcta.
\ Esto es equivalente a un estudiante que muestra un trabajo sin sentido en un examen de matemáticas pero milagrosamente escribe el número final correcto. No concluirías que entienden el material; sospecharías que copiaron la respuesta. En IA, esto sugiere que el "razonamiento" es a menudo una justificación post-hoc, no un proceso de pensamiento genuino. Esto no es un error que se solucione escalando; el problema empeora con modelos más avanzados, con la tasa de este comportamiento contradictorio aumentando al 74% en GPT-4.
\ Si el "proceso de pensamiento" interno del modelo es un espejismo, ¿qué sucede cuando se le obliga a resolver un problema real y complejo? A menudo, desciende a la locura.
Quedan Atrapados en Bucles de "Descenso a la Locura"
Al usar LLMs para tareas complejas como depurar código, puede surgir un patrón peligroso: un "descenso a la locura" o un "bucle de alucinación". Este es un ciclo de retroalimentación donde un LLM, intentando corregir un error de programación, queda atrapado en un bucle irracional sin fin. Sugiere una solución aparentemente plausible que falla, y cuando se le pide otra solución, a menudo reintroduce el error original, atrapando al usuario en un ciclo infructuoso.
\ Un estudio que encargó a programadores depurar código reveló una tendencia impactante para los flujos de trabajo asistidos por IA. Los resultados fueron claros: los programadores no asistidos por IA resolvieron más tareas correctamente y menos tareas incorrectamente que el grupo que utilizó LLMs para ayuda.
\ Reflexiona sobre esto: en una tarea compleja de depuración, tener un asistente de IA de última generación no solo no era útil, sino que era activamente perjudicial, llevando a peores resultados que no tener IA en absoluto. Los participantes que usaban IA frecuentemente quedaban atrapados en estos bucles infructuosos, perdiendo tiempo en correcciones conceptualmente sin fundamento. Los investigadores también identificaron el problema de la "solución ruidosa", donde una corrección correcta está enterrada dentro de una avalancha de sugerencias irrelevantes, una receta perfecta para la frustración humana. Esta "asistencia" defectuosa destaca cómo el impresionante barniz de la IA puede ocultar un núcleo profundamente poco fiable, especialmente cuando las apuestas son altas.
Sus Impresionantes Benchmarks Están Construidos Sobre una Base de Fallos
Cuando las empresas de IA lanzan nuevos modelos, señalan impresionantes puntuaciones de referencia para demostrar su superioridad. Una mirada más cercana, sin embargo, puede revelar una imagen mucho menos halagadora.
\ El SWE-bench (Software Engineering Benchmark), utilizado para medir la capacidad de un LLM para solucionar problemas de software del mundo real desde GitHub, es un caso de estudio principal. Un estudio independiente de la Universidad de York encontró fallos críticos que inflaron salvajemente las capacidades percibidas de los modelos:
\
- Filtración de Soluciones ("Trampa"): En el 32,67% de los parches exitosos, la solución correcta ya estaba proporcionada en el informe del problema mismo.
- Pruebas Débiles: En el 31,08% de los casos donde el modelo "pasó", las pruebas de verificación eran demasiado débiles para confirmar realmente que la corrección era correcta.
\ Cuando estas instancias defectuosas fueron filtradas, el rendimiento en el mundo real de un modelo superior (SWE-Agent + GPT-4) se desplomó. Su tasa de resolución cayó de un anunciado 12,47% a solo 3,97%. Además, más del 94% de los problemas en el benchmark fueron creados antes de las fechas de corte de conocimiento de los LLMs, planteando serias preguntas sobre la filtración de datos.
\ Esto revela una realidad preocupante: los benchmarks son a menudo herramientas de marketing que presentan un escenario de mejor caso, cultivado en laboratorio, que se desmorona bajo el escrutinio del mundo real. La brecha entre el poder anunciado y el rendimiento verificado no es una grieta; es un cañón.
Dominan las Reglas Pero Fundamentalmente Carecen de Comprensión
Incluso si todos los fallos técnicos anteriores fueran corregidos, permanece una barrera más profunda y filosófica. Los LLMs carecen de los componentes centrales de la inteligencia humana. Mientras los filósofos discuten la conciencia y la intencionalidad, muchos argumentos sugieren que la racionalidad, es decir, nuestra capacidad para captar conceptos universales y razonar lógicamente, es el aspecto clave único de los humanos y ausente en la IA.
\ Esta idea es reforzada por el físico Roger Penrose, quien utiliza el teorema de incompletitud de Gödel para argumentar que la comprensión matemática humana trasciende cualquier conjunto fijo de reglas algorítmicas. Piensa en cualquier algoritmo como un libro de reglas finito. El teorema de Gödel muestra que un matemático humano siempre puede mirar el libro de reglas desde fuera y entender verdades que el propio libro de reglas no puede probar.
\ Nuestras mentes no solo siguen las reglas del libro; podemos leer todo el libro y captar sus limitaciones. Esta capacidad de perspicacia, esta comprensión "no computable", es lo que separa la cognición humana incluso de la IA más avanzada.
\ Los LLMs son maestros en manipular símbolos basados en algoritmos y patrones estadísticos. Sin embargo, no poseen la conciencia requerida para una comprensión genuina. Como concluye un poderoso argumento:
El Truco del Mago
Aunque los LLMs son innegablemente herramientas poderosas que pueden simular comportamiento inteligente con precisión inquietante, la creciente evidencia muestra que son más como simuladores sofisticados que pensadores genuinos. Su rendimiento es una gran ilusión, un espectáculo deslumbrante de competencia que se desmorona bajo presión, contradice su propia lógica y se basa en métricas defectuosas. Es similar al truco de un mago (aparentemente imposible), pero en última instancia una ilusión construida sobre técnicas inteligentes, no magia real. A medida que continuamos integrando estos sistemas en nuestro mundo, debemos permanecer críticos y hacer la pregunta esencial:
\ Si estas máquinas de IA se descomponen en problemas más difíciles, incluso cuando les das los algoritmos y las reglas, ¿están realmente pensando o solo fingiéndolo muy bien?
Podcast:
\
- Apple: AQUÍ
- Spotify: AQUÍ
\
También te puede interesar

DTCC lista el ETF spot de Chainlink de Bitwise bajo el ticker CLNK

Polymarket y PrizePicks se unen para un crecimiento explosivo en los mercados de predicción de 2025
