

DiverGen hace que el entrenamiento de segmentación de instancias a gran escala sea más efectivo
:::info Autores:
(1) Chengxiang Fan, con igual contribución de la Universidad de Zhejiang, China;
(2) Muzhi Zhu, con igual contribución de la Universidad de Zhejiang, China;
(3) Hao Chen, Universidad de Zhejiang, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Universidad de Zhejiang, China;
(5) Weijia Wu, Universidad de Zhejiang, China;
(6) Huaqi Zhang, vivo Mobile Communication Co..
(7) Chunhua Shen, Universidad de Zhejiang, China (chunhuashen@zju.edu.cn).
:::
Tabla de Enlaces
Resumen y 1 Introducción
-
Trabajo Relacionado
-
Nuestro DiverGen Propuesto
3.1. Análisis de Distribución de Datos
3.2. Mejora de Diversidad de Datos Generativos
3.3. Pipeline Generativo
-
Experimentos
4.1. Configuraciones
4.2. Resultados Principales
4.3. Estudios de Ablación
-
Conclusiones, Agradecimientos y Referencias
\ Apéndice
A. Detalles de Implementación
B. Visualización
Resumen
La segmentación de instancias requiere muchos datos, y a medida que aumenta la capacidad del modelo, la escala de datos se vuelve crucial para mejorar la precisión. La mayoría de los conjuntos de datos de segmentación de instancias actuales requieren costosas anotaciones manuales, limitando su escala. Los modelos entrenados con estos datos tienden a sobreajustarse al conjunto de entrenamiento, especialmente para categorías raras. Aunque trabajos recientes han profundizado en el uso de modelos generativos para crear conjuntos de datos sintéticos para aumentación de datos, estos enfoques no aprovechan eficientemente todo el potencial de los modelos generativos.
\ Para abordar estos problemas, introducimos una estrategia más eficiente para construir conjuntos de datos generativos para aumentación de datos, denominada DiverGen. Primero, proporcionamos una explicación del papel de los datos generativos desde la perspectiva de la discrepancia de distribución. Investigamos el impacto de diferentes datos en la distribución aprendida por el modelo. Argumentamos que los datos generativos pueden expandir la distribución de datos que el modelo puede aprender, mitigando así el sobreajuste. Además, encontramos que la diversidad de los datos generativos es crucial para mejorar el rendimiento del modelo y la mejoramos a través de varias estrategias, incluyendo diversidad de categorías, diversidad de prompts y diversidad de modelos generativos. Con estas estrategias, podemos escalar los datos a millones mientras mantenemos la tendencia de mejora del rendimiento del modelo. En el conjunto de datos LVIS, DiverGen supera significativamente al potente modelo X-Paste, logrando +1.1 box AP y +1.1 mask AP en todas las categorías, y +1.9 box AP y +2.5 mask AP para categorías raras. Nuestro código está disponible en https://github.com/aim-uofa/DiverGen.
1. Introducción
La segmentación de instancias [2, 4, 9] es una de las tareas desafiantes en visión por computadora, que requiere la predicción de máscaras y categorías para instancias en una imagen, lo que sirve como base para numerosas aplicaciones visuales. A medida que mejoran las capacidades de aprendizaje de los modelos, aumenta la demanda de datos de entrenamiento. Sin embargo, los conjuntos de datos actuales para segmentación de instancias dependen en gran medida de anotaciones manuales, lo que consume tiempo y es costoso, y la escala del conjunto de datos no puede satisfacer las necesidades de entrenamiento de los modelos. A pesar de la reciente aparición del conjunto de datos anotado automáticamente SA-1B [12], carece de anotaciones de categoría, no cumpliendo con los requisitos de segmentación de instancias. Mientras tanto, el desarrollo continuo del modelo generativo ha mejorado en gran medida la controlabilidad y el realismo de las muestras generadas. Por ejemplo, el reciente modelo de difusión text2image [22, 24] puede generar imágenes de alta calidad correspondientes a los prompts de entrada. Por lo tanto, los métodos actuales [27, 28, 34] utilizan modelos generativos para aumentación de datos generando conjuntos de datos para complementar el entrenamiento de modelos en conjuntos de datos reales y mejorar el rendimiento del modelo. Aunque los métodos actuales han propuesto varias estrategias para permitir que los datos generativos mejoren el rendimiento del modelo, todavía existen algunas limitaciones: 1) Los métodos existentes no han explotado completamente el potencial de los modelos generativos. Primero, algunos métodos [34] no solo usan datos generativos sino que también necesitan rastrear imágenes de internet, lo que es significativamente desafiante para obtener datos a gran escala. Mientras tanto, el contenido de los datos extraídos de internet es incontrolable y necesita verificación adicional. Segundo, los métodos existentes no utilizan completamente la controlabilidad de los modelos generativos. Los métodos actuales a menudo adoptan plantillas diseñadas manualmente para construir prompts, limitando la salida potencial de los modelos generativos. 2) Los métodos existentes [27, 28] a menudo explican el papel de los datos generativos desde la perspectiva del desequilibrio de clases o la escasez de datos, sin considerar la discrepancia entre los datos del mundo real y los datos generativos. Además, estos métodos típicamente muestran un rendimiento mejorado del modelo solo en escenarios con un número limitado de muestras reales, y la efectividad de los datos generativos en conjuntos de datos reales a gran escala existentes, como LVIS [8], no se investiga a fondo.
\ En este artículo, primero exploramos el papel de los datos generativos desde la perspectiva de la discrepancia de distribución, abordando dos preguntas principales: 1) ¿Por qué la aumentación de datos generativos mejora el rendimiento del modelo? 2) ¿Qué tipos de datos generativos son beneficiosos para mejorar el rendimiento del modelo? Primero, encontramos que existen discrepancias entre la distribución aprendida por el modelo de los datos de entrenamiento reales limitados y la distribución de los datos del mundo real. Visualizamos los datos y encontramos que, en comparación con los datos del mundo real, los datos generativos pueden expandir la distribución de datos que el modelo puede aprender. Además, encontramos que el papel de agregar datos generativos es aliviar el sesgo de los datos de entrenamiento reales, mitigando efectivamente el sobreajuste de los datos de entrenamiento. Segundo, encontramos que también hay discrepancias entre la distribución de los datos generativos y la distribución de datos del mundo real. Si estas discrepancias no se manejan adecuadamente, no se puede utilizar todo el potencial del modelo generativo. Al realizar varios experimentos, encontramos que el uso de datos generativos diversos permite a los modelos adaptarse mejor a estas discrepancias, mejorando el rendimiento del modelo.
\ Basándonos en el análisis anterior, proponemos una estrategia eficiente para mejorar la diversidad de datos, a saber, Mejora de Diversidad de Datos Generativos. Diseñamos varias estrategias de mejora de diversidad para aumentar la diversidad de datos desde las perspectivas de diversidad de categorías, diversidad de prompts y diversidad de modelos generativos. Para la diversidad de categorías, observamos que los modelos entrenados con datos generativos que cubren todas las categorías se adaptan mejor a la discrepancia de distribución que los modelos entrenados con categorías parciales. Por lo tanto, introducimos no solo categorías de LVIS [8] sino también categorías adicionales de ImageNet-1K [23] para mejorar la diversidad de categorías en la generación de datos, reforzando así la adaptabilidad del modelo a la discrepancia de distribución. Para la diversidad de prompts, encontramos que a medida que aumenta la escala del conjunto de datos generativo, los prompts diseñados manualmente no pueden escalar al nivel correspondiente, limitando la diversidad de imágenes de salida del modelo generativo. Por lo tanto, diseñamos un conjunto de estrategias diversas de generación de prompts para usar modelos de lenguaje grandes, como ChatGPT, para la generación de prompts, requiriendo que los modelos de lenguaje grandes produzcan prompts maximalmente diversos bajo restricciones. Al combinar prompts diseñados manualmente y prompts diseñados por ChatGPT, enriquecemos efectivamente la diversidad de prompts y mejoramos aún más la diversidad de datos generativos. Para la diversidad de modelos generativos, encontramos que los datos de diferentes modelos generativos también exhiben discrepancias de distribución. Exponer a los modelos a datos de diferentes modelos generativos durante el entrenamiento puede mejorar la adaptabilidad a diferentes distribuciones. Por lo tanto, empleamos Stable Diffusion [22] y DeepFloyd-IF [24] para generar imágenes para todas las categorías por separado y mezclamos los dos tipos de datos durante el entrenamiento para aumentar la diversidad de datos.
\ Al mismo tiempo, optimizamos el flujo de trabajo de generación de datos y proponemos un pipeline generativo de cuatro etapas que consiste en generación de instancias, anotación de instancias, filtración de instancias y aumentación de instancias. En la etapa de generación de instancias, empleamos nuestra propuesta de Mejora de Diversidad de Datos Generativos para mejorar la diversidad de datos, produciendo datos brutos diversos. En la etapa de anotación de instancias, introducimos una estrategia de anotación llamada SAM-background. Esta estrategia obtiene anotaciones de alta calidad utilizando puntos de fondo como prompts de entrada para SAM [12], obteniendo las anotaciones de los datos brutos. En la etapa de filtración de instancias, introducimos una métrica llamada inter-similitud CLIP. Utilizando el codificador de imágenes CLIP [21], extraemos embeddings de datos generativos y reales, y luego calculamos su similitud. Una similitud más baja indica una calidad de datos más baja. Después de la filtración, obtenemos el conjunto de datos generativo final. En la etapa de aumentación de instancias, utilizamos la estrategia de pegado de instancias [34] para aumentar la eficiencia de aprendizaje del modelo en datos generativos.
\ Los experimentos demuestran que nuestras estrategias de diversidad de datos diseñadas pueden mejorar efectivamente el rendimiento del modelo y mantener la tendencia de ganancias de rendimiento a medida que la escala de datos aumenta al nivel de millones, lo que permite datos generativos a gran escala para aumentación de datos. En el conjunto de datos LVIS, DiverGen supera significativamente al potente modelo X-Paste [34], logrando +1.1 box AP [8] y +1.1 mask AP en todas las categorías, y +1.9 box AP y +2.5 mask AP para categorías raras.
\ En resumen, nuestras principales contribuciones son las siguientes:
\ • Explicamos el papel de los datos generativos desde la perspectiva de la discrepancia de distribución. Encontramos que los datos generativos pueden expandir la distribución de datos que el modelo puede aprender, mitigando el sobreajuste del conjunto de entrenamiento y la diversidad de los datos generativos es crucial para mejorar el rendimiento del modelo.
\ • Proponemos la estrategia de Mejora de Diversidad de Datos Generativos para aumentar la diversidad de datos desde los aspectos de diversidad de categorías, diversidad de prompts y diversidad de modelos generativos. Al mejorar la diversidad de datos, podemos escalar los datos a millones mientras mantenemos la tendencia de mejora del rendimiento del modelo.
\ • Optimizamos el pipeline de generación de datos. Proponemos una estrategia de anotación SAM-background para obtener anotaciones de mayor calidad. También introducimos una métrica de filtración llamada inter-similitud CLIP para filtrar datos y mejorar aún más la calidad del conjunto de datos generativo.
2. Trabajo Relacionado
Segmentación de instancias. La segmentación de instancias es una tarea importante en el campo de la visión por computadora y ha sido ampliamente estudiada. A diferencia de la segmentación semántica, la segmentación de instancias no solo clasifica los píxeles a nivel de píxel sino que también distingue diferentes instancias de la misma categoría. Anteriormente, el enfoque de la investigación de segmentación de instancias ha sido principalmente en el diseño de estructuras de modelos. Mask-RCNN [9] unifica las tareas de detección de objetos y segmentación de instancias. Posteriormente, Mask2Former [4] unificó aún más las tareas de segmentación semántica y segmentación de instancias aprovechando la estructura de DETR [2].
\ Ortogonal a estos estudios centrados en la arquitectura del modelo, nuestro trabajo investiga principalmente cómo utilizar mejor los datos generados para esta tarea. Nos centramos en el desafiante
\ 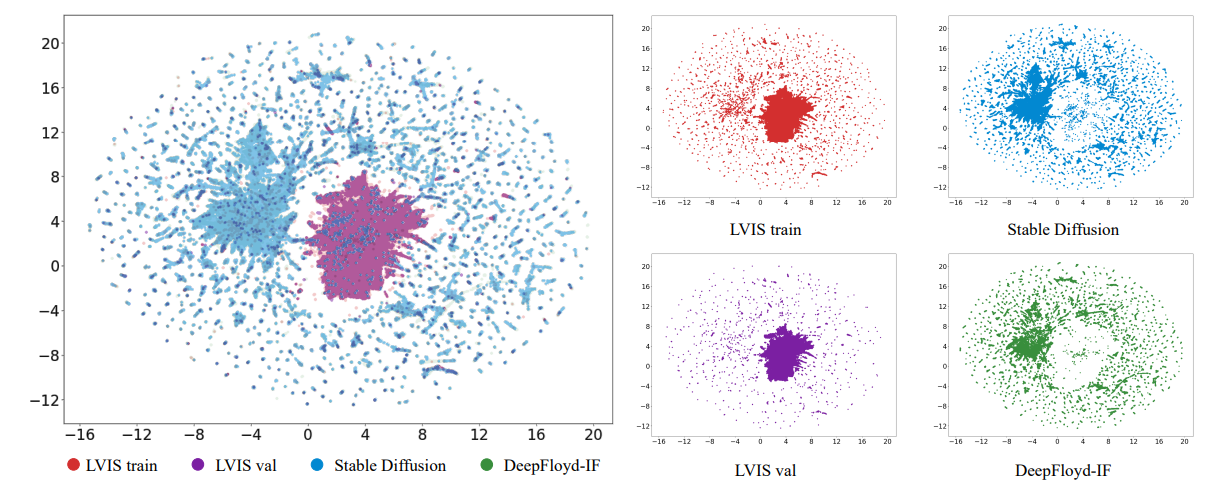
\ conjunto de datos de cola larga LVIS [8] porque son solo las categorías de cola larga las que enfrentan el problema de datos reales limitados y requieren imágenes generativas para aumentación, haciéndolo más significativo en la práctica.
\ Aumentación de datos generativos. El uso de modelos generativos para sintetizar datos de entrenamiento para asistir tareas de percepción como clasificación [6, 32], detección [3, 34], segmentación [14
También te puede interesar

Las Guerras de Liquidez Borran Miles de Millones: Andrei Grachev de DWF Labs Hace Sonar la Alarma

Cambio de volumen en los mercados de criptomonedas: De las monedas establecidas a la preventa de IA de IPO Genie
