

Cómo los modelos híbridos de IA equilibran la memoria y la eficiencia
Tabla de Enlaces
Resumen y 1. Introducción
-
Metodología
-
Experimentos y Resultados
3.1 Modelado de Lenguaje en Datos vQuality
3.2 Exploración sobre Atención y Recurrencia Lineal
3.3 Extrapolación Eficiente de Longitud
3.4 Comprensión de Contexto Largo
-
Análisis
-
Conclusión, Agradecimientos y Referencias
A. Detalles de Implementación
B. Resultados Adicionales de Experimentos
C. Detalles de Medición de Entropía
D. Limitaciones
\
A Detalles de Implementación
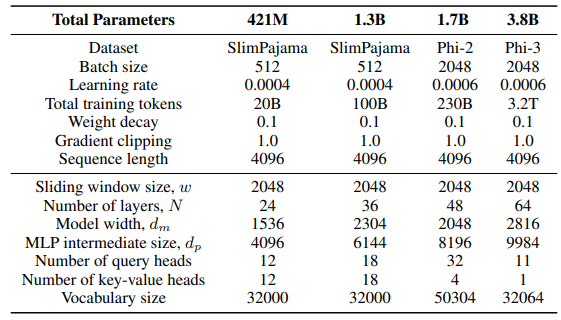
\ Para la capa GLA en la arquitectura Sliding GLA, utilizamos el número de cabezas dm/384, una proporción de expansión de clave de 0.5 y una proporción de expansión de valor de 1. Para la capa RetNet utilizamos un número de cabezas que es la mitad del número de cabezas de consulta de atención, proporción de expansión de clave de 1 y proporción de expansión de valor de 2. Las implementaciones de GLA y RetNet son del repositorio Flash Linear Attention[3] [YZ24]. Utilizamos la implementación basada en FlashAttention para la extrapolación Self-Extend[4]. El modelo Mamba 432M tiene un ancho de modelo de 1024 y el modelo Mamba 1.3B tiene un ancho de modelo de 2048. Todos los modelos entrenados en SlimPajama tienen las mismas configuraciones de entrenamiento y el tamaño intermedio MLP que Samba, a menos que se especifique lo contrario. La infraestructura de entrenamiento en SlimPajama se basa en una versión modificada del código base TinyLlama[5].
\ 
\ En las configuraciones de generación para las tareas posteriores, utilizamos decodificación voraz para GSM8K y Nucleus Sampling [HBD+19] con una temperatura de τ = 0.2 y top-p = 0.95 para HumanEval. Para MBPP y SQuAD, establecemos τ = 0.01 y top-p = 0.95.
B Resultados Adicionales de Experimentos
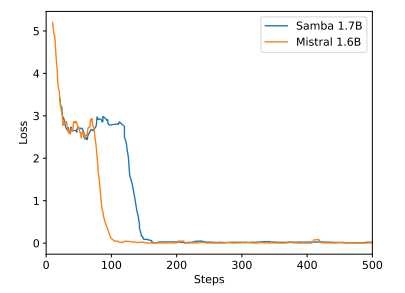
\ 
\ 
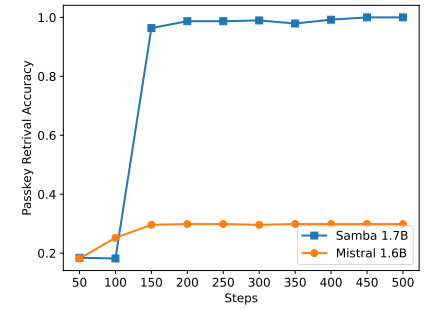
\ 
\
C Detalles de Medición de Entropía
\ 
\
D Limitaciones
Aunque Samba demuestra un rendimiento prometedor de recuperación de memoria a través del ajuste de instrucciones, su modelo base pre-entrenado tiene un rendimiento de recuperación similar al del modelo basado en SWA, como se muestra en la Figura 7. Esto abre una dirección futura para mejorar aún más la capacidad de recuperación de Samba sin comprometer su eficiencia y capacidad de extrapolación. Además, la estrategia de hibridación de Samba no es consistentemente mejor que otras alternativas en todas las tareas. Como se muestra en la Tabla 2, MambaSWA-MLP muestra un rendimiento mejorado en tareas como WinoGrande, SIQA y GSM8K. Esto nos da el potencial para invertir en un enfoque más sofisticado para realizar combinaciones dinámicas dependientes de la entrada de modelos basados en SWA y modelos basados en SSM.
\
:::info Autores:
(1) Liliang Ren, Microsoft y University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Este artículo está disponible en arxiv bajo licencia CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
También te puede interesar

Pronóstico de Forex y Criptomonedas para el 27-31 de octubre de 2025

El rendimiento regulado de criptomonedas triunfa mientras las instituciones exigen sustancia
