

Nueva configuración de IIL: Mejorando los modelos implementados solo con datos nuevos
Tabla de Enlaces
Resumen y 1 Introducción
-
Trabajos relacionados
-
Planteamiento del problema
-
Metodología
4.1. Destilación consciente de límites de decisión
4.2. Consolidación de conocimiento
-
Resultados experimentales y 5.1. Configuración del experimento
5.2. Comparación con métodos SOTA
5.3. Estudio de ablación
-
Conclusión y trabajo futuro y Referencias
\
Material Complementario
- Detalles del análisis teórico sobre el mecanismo KCEMA en IIL
- Visión general del algoritmo
- Detalles del conjunto de datos
- Detalles de implementación
- Visualización de imágenes de entrada con polvo
- Más resultados experimentales
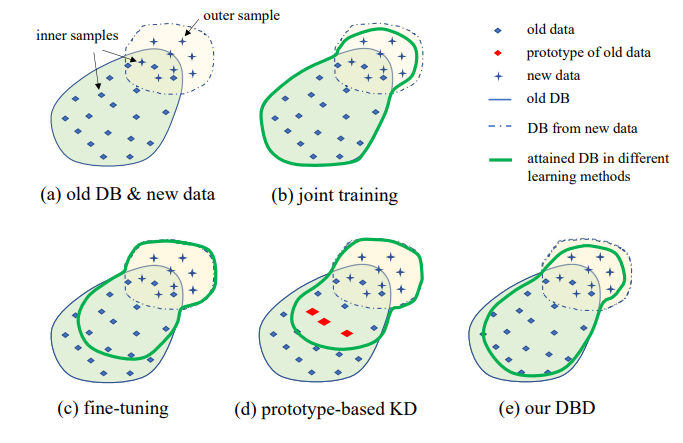
3. Planteamiento del problema
La ilustración del entorno IIL propuesto se muestra en la Fig. 1. Como se puede ver, los datos se generan de manera continua e impredecible en el flujo de datos. Generalmente en aplicaciones reales, las personas tienden a recopilar primero suficientes datos y entrenar un modelo fuerte M0 para su implementación. No importa cuán fuerte sea el modelo, inevitablemente encontrará datos fuera de distribución y fallará en ellos. Estos casos fallidos y otras nuevas observaciones de baja puntuación serán anotados para entrenar el modelo de vez en cuando. Reentrenar el modelo con todos los datos acumulados cada vez conlleva un costo cada vez mayor en tiempo y recursos. Por lo tanto, el nuevo IIL busca mejorar el modelo existente utilizando solo los nuevos datos cada vez.
\ 
\ 
\
:::info Autores:
(1) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Universidad de Ciencia y Tecnología de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC BY-NC-ND 4.0 Deed (Atribución-NoComercial-SinDerivadas 4.0 Internacional).
:::
\
También te puede interesar

Reddit, Kick añadidos a la creciente lista negra de redes sociales para adolescentes de Australia

Estas Altcoins generando ingresos mientras el mercado cae: Aquí están los proyectos que generan más ingresos
