

بهینهسازی هزینه و استفاده از کلاستر Databricks بدون جداول سیستمی
در اکثر محیطهای سازمانی Databricks (مانند MSC یا اکوسیستمهای تحلیلی بزرگ)، جداول سیستمی مانند system.job_run_logs یا system.cluster_events ممکن است به دلیل سیاستهای امنیتی یا حاکمیتی محدود یا غیرفعال شده باشند.
با این حال، ردیابی استفاده از کلاستر و هزینه برای موارد زیر حیاتی است:
- درک نحوه استفاده کارآمد تسکها از منابع محاسباتی
- شناسایی کلاسترهای بیکار یا نشت هزینه
- پیشبینی بودجه زیرساختی
- ساخت داشبوردهای سفارشی هزینه
این وبلاگ یک رویکرد گام به گام برای محاسبه استفاده از کلاستر و هزینه را تنها با استفاده از Databricks REST APIs نشان میدهد — بدون نیاز به جداول سیستمی.
مورد استفاده پروژه
در پلتفرم داده MSC ما، چندین کلاستر Databricks را در محیطهای توسعه، تست و تولید اجرا میکنیم. \n ما با سه چالش اصلی مواجه بودیم:
- عدم دسترسی به جداول سیستمی (محدود شده توسط سیاستهای مدیریتی)
- کلاسترهای موقت برای تسکهایی که به صورت پویا توسط ADF یا پایپلاینهای هماهنگسازی ایجاد میشوند
- عدم دید مستقیم از نحوه تبدیل استفاده از کلاستر به هزینه
بنابراین، یک تحلیلگر سبک استفاده ساختیم که:
- داده را از Databricks REST APIs دریافت میکند
- زمان اجرای تسک در مقابل زمان اجرای کلاستر را محاسبه میکند
- هزینه را با استفاده از نرخهای DBU و VM تخمین میزند
- یک DataFrame قابل استفاده آسان خروجی میدهد
مشکل و رویکرد
چالش شناسایی شده
تیمها اغلب نیاز دارند بدانند:
- کدام کلاسترها بیکار هستند (در حال اجرا با فعالیت تسک پایین)؟
- درصد استفاده چقدر است (زمان اجرای تسک در مقابل زمان فعال بودن کلاستر)؟
- هر کلاستر چقدر هزینه دارد (DBU + VM)؟
وقتی جداول سیستمی Unity Catalog (مثلاً system.job_run_logs) در دسترس نیستند، رویکرد پیشفرض مبتنی بر SQL شکست میخورد. REST API به یک جایگزین قابل اعتماد تبدیل میشود.
رویکرد سطح بالا استفاده شده در دفترچه یادداشت
- لیست کلاسترها از طریق /api/2.0/clusters/list.
- تخمین زمان فعال بودن کلاستر با استفاده از برچسبهای زمانی داخل JSON کلاستر (فیلدهای created/start/terminated). (این یک جایگزین عملی است وقتی /clusters/events در دسترس نیست.)
- دریافت اجراهای اخیر تسک با استفاده از /api/2.1/jobs/runs/list با فیلترهای زمانی (یا محدودیت).
- تطبیق اجراهای تسک با کلاسترها با استفاده از cluster_instance.cluster_id (یا سایر متادیتاهای کلاستر).
- محاسبه استفاده: درصد استفاده = total_job_runtime / total_cluster_uptime.
- تخمین هزینه با استفاده از فرمول ساده: هزینه = running_hours × (DBU/hr × فرض شده DBU) + running_hours × nodes × VM $/hr.
این دفترچه یادداشت عمداً از پرسوجوهای محدود استفاده میکند (N اجرای آخر، پنجره زمانی) تا سریع اجرا شود.
\ ۱. راهاندازی و پیکربندی
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ این بخش موارد زیر را مقداردهی اولیه میکند:
- آدرس فضای کاری و توکن برای احراز هویت
- بازه زمانی که میخواهید استفاده را تحلیل کنید
- فرضیات هزینه:
- نرخ DBU ($/hr به ازای هر DBU)
- هزینه نود VM
- مصرف تقریبی DBU
در تنظیمات سازمانی، این نرخها میتوانند به صورت پویا از طریق FinOps یا APIهای صورتحساب شما دریافت شوند.
-
تابع Wrapper API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ این تابع کمکی همه فراخوانیهای GET REST API را استاندارد میکند. \n این:
-
آدرس کامل نقطه پایانی را میسازد
-
404 را به آرامی مدیریت میکند (مهم است وقتی کلاسترها یا اجراها منقضی شدهاند)
-
JSON تجزیه شده را برمیگرداند
چرا اهمیت دارد: این تابع ارتباط تمیز API را بدون شکستن جریان دفترچه یادداشت شما اگر هر داده کلاستری گم شده باشد، تضمین میکند.
\
-
لیست همه کلاسترهای فعال
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ این همه کلاسترهای موجود در فضای کاری شما را بازیابی میکند. \n معادل مشاهده برنامهنویسی برگه "محاسبه" شما است. \n پاسخ شامل موارد زیر است:
-
شناسههای کلاستر
-
نامها
-
تعداد نودها
-
اطلاعات سازنده
-
زمانهای ایجاد و خاتمه
مورد استفاده: کمک به شناسایی کدام کلاسترها منابع را مصرف میکنند در پنجره انتخاب شده.
۴. تخمین زمان اجرای کلاستر
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ ما کل ساعات اجرا را برای هر کلاستر محاسبه میکنیم:
-
از برچسبهای زمانی ایجاد و خاتمه استفاده میکند
-
کلاسترهای در حال اجرا را مدیریت میکند (terminated_time گم شده)
-
به ساعت نرمالسازی میکند
چرا مهم است: این مقدار مخرج برای استفاده است — نمایانگر کل زمان فعال بودن کلاستر در طول پنجره.
۵. دریافت اجراهای اخیر تسک
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ به جای واکشی کل تاریخچه تسک (که کند است)، \n این تابع ۱۰ اجرای اخیر تسک را برای تشخیص سریع بازیابی میکند.
در تولید، میتوانید فیلتر کنید بر اساس:
- job_id خاص
- completed_only=true
- پنجره تاریخ (start_time_from، start_time_to)
\
-
محاسبه استفاده و هزینه
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
این قلب منطق است:
-
حلقه از طریق هر کلاستر
-
محاسبه کل زمان اجرای تسک به ازای هر کلاستر (با استفاده از API اجراهای تسک)
-
استخراج درصد استفاده = (job_hours / cluster_running_hours) × 100
-
تخمین هزینه:
- هزینه DBU بر اساس نرخ × DBU/hr
- هزینه VM = node_count × node_cost/hr × running_hours
چرا اهمیت دارد: \n این یک تصویر یکپارچه از کارایی و هزینه ارائه میدهد — مفید برای شناسایی کلاسترها با هزینه بالا اما استفاده پایین.
۷. هماهنگسازی پایپلاین
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ این بلوک نهایی:
-
داده را بازیابی میکند
-
محاسبه هزینه را انجام میدهد
-
Data Frame مرتب شده را نمایش میدهد
در عمل، این Data Frame میتواند:
-
به Excel یا Delta Table صادر شود
-
به داشبوردهای Power BI ارسال شود
-
در پایپلاینهای اتوماسیون FinOps یکپارچه شود
\
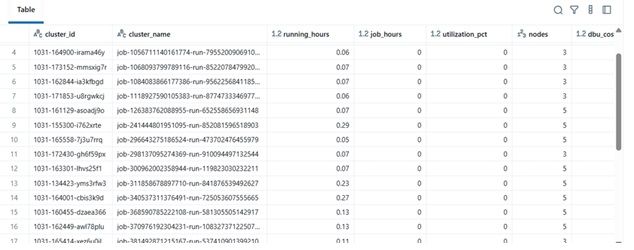
مثال نتایج
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
مزیت دنیای واقعی
با پیادهسازی این تحلیلگر:
-
تیمهای مهندسی میتوانند هزینه کلاستر را حتی بدون دسترسی به حسابرسی ردیابی کنند.
-
مدیران دید به کلاسترهای کم استفاده پیدا میکنند.
-
DevOps میتواند به طور خودکار کلاسترهای کم استفاده را خاتمه دهد.
-
امور مالی میتواند فاکتورهای Databricks را با معیارهای داخلی اعتبارسنجی کند.
در پروژه MSC ما، از این به عنوان بخشی از پشته قابلیت مشاهده پلتفرم داده خود استفاده کردیم — ترکیب داده REST API، لاگهای تسک ADF و روندهای هزینه در یک داشبورد یکپارچه.
\
محتوای پیشنهادی

نزدک و CME شاخص جدید نزدک-CME ارز دیجیتال را راهاندازی کردند—یک تحول بزرگ در داراییهای دیجیتال

قانون CLARITY نیاز به حمایت دوحزبی در کمیته بانکداری سنا دارد: تحلیلگر
