

Voici pourquoi les chercheurs en IA parlent de l'entraînement spectral clairsemé
Table des Liens
Abstrait et 1. Introduction
-
Travaux Connexes
-
Adaptation de Rang Faible
3.1 LoRA et 3.2 Limitation de LoRA
3.3 ReLoRA*
-
Entraînement Spectral Sparse
4.1 Préliminaires et 4.2 Mise à jour du gradient de U, VT avec Σ
4.3 Pourquoi l'initialisation SVD est importante
4.4 SST équilibre exploitation et exploration
4.5 Implémentation économe en mémoire pour SST et 4.6 Sparsité de SST
-
Expériences
5.1 Traduction automatique
5.2 Génération de langage naturel
5.3 Réseaux de neurones graphiques hyperboliques
-
Conclusion et Discussion
-
Impacts plus larges et Références
Informations Supplémentaires
A. Algorithme d'Entraînement Spectral Sparse
B. Preuve du Gradient de la Couche Spectrale Sparse
C. Preuve de la Décomposition du Gradient du Poids
D. Preuve de l'Avantage du Gradient Amélioré sur le Gradient par Défaut
E. Preuve de Distorsion Zéro avec Initialisation SVD
F. Détails des Expériences
G. Élagage des Valeurs Singulières
H. Évaluation de SST et GaLore : Approches Complémentaires pour l'Efficacité de la Mémoire
I. Étude d'Ablation
A Algorithme d'Entraînement Spectral Sparse
B Preuve du Gradient de la Couche Spectrale Sparse
Nous pouvons exprimer le différentiel de W comme la somme des différentiels :
\ \ 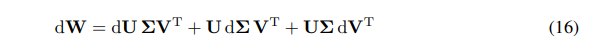
\ \ Nous avons la règle de chaîne pour le gradient de W :
\ \ 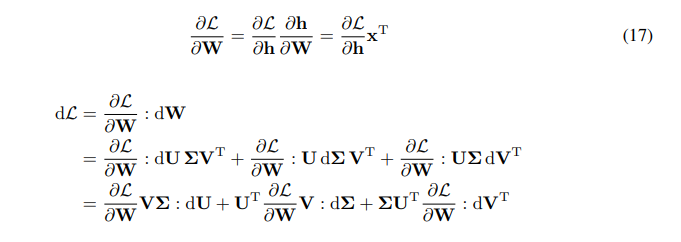
\ \ \ 
\
C Preuve de la Décomposition du Gradient du Poids
\ 
\
D Preuve de l'Avantage du Gradient Amélioré sur le Gradient par Défaut
\ 
\ \ \ 
\ \ \ 
\ \ Comme seule la direction de la mise à jour compte, l'échelle de la mise à jour peut être ajustée en modifiant le taux d'apprentissage. Nous mesurons la similarité en utilisant la norme de Frobenius des différences entre les mises à jour SST et 3 fois la mise à jour de rang complet.
\ \ 
\
E Preuve de Distorsion Zéro avec Initialisation SVD
\ 
F Détails des Expériences
F.1 Détails d'Implémentation pour SST
\ 
\ \ \ 
\
F.2 Hyperparamètres de la Traduction Automatique
IWSLT'14. Les hyperparamètres se trouvent dans le Tableau 6. Nous utilisons la même base de code et les mêmes hyperparamètres que ceux utilisés dans HyboNet [12], qui est dérivé d'OpenNMT-py [54]. Le point de contrôle final du modèle est utilisé pour l'évaluation. La recherche en faisceau, avec une taille de faisceau de 2, est employée pour optimiser le processus d'évaluation. Les expériences ont été menées sur un GPU A100.
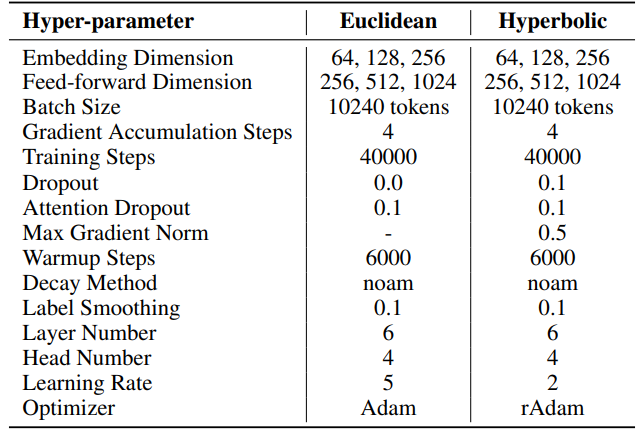
\ Pour SST, le nombre d'étapes par itération (T3) est fixé à 200. Chaque itération commence par une phase de préchauffage durant 20 étapes. Le nombre d'itérations par tour (T2) est déterminé par la formule T2 = d/r, où d représente la dimension d'intégration et r désigne le rang utilisé dans SST.
\ \ 
\ \ \ 
\ \ Pour SST, le nombre d'étapes par itération (T3) est fixé à 200 pour Multi30K et 400 pour IWSLT'17. Chaque itération commence par une phase de préchauffage durant 20 étapes. Le nombre d'itérations par tour (T2) est déterminé par la formule T2 = d/r, où d représente la dimension d'intégration et r désigne le rang utilisé dans SST
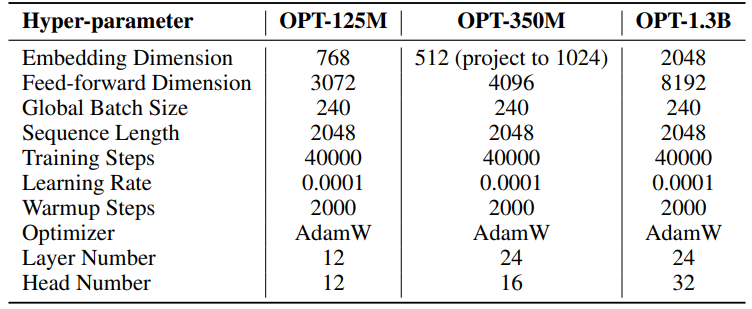
F.3 Hyperparamètres de la Génération de Langage Naturel
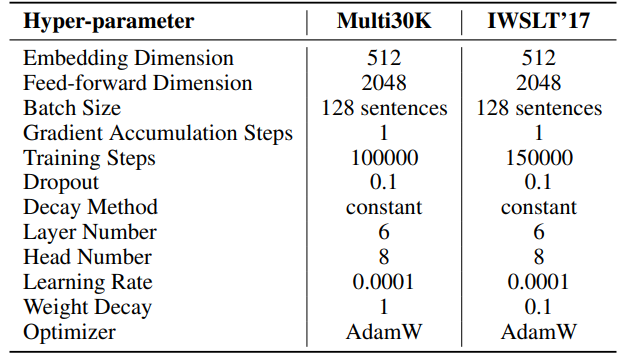
Les hyperparamètres de nos expériences sont détaillés dans le Tableau 8. Nous employons un préchauffage linéaire de 2000 étapes suivi d'un taux d'apprentissage stable, sans décroissance. Un taux d'apprentissage plus élevé (0,001) est utilisé uniquement pour les paramètres de rang faible (U, VT et Σ pour SST, B et A pour LoRA et ReLoRA*. Le total des jetons d'entraînement pour chaque expérience est de 19,7 milliards, soit environ 2 époques d'OpenWebText. L'entraînement distribué est facilité par la bibliothèque Accelerate [55] sur quatre GPU A100 sur un serveur Linux.
\ Pour SST, le nombre d'étapes par itération (T3) est fixé à 200. Chaque itération commence par une phase de préchauffage durant 20 étapes. Le nombre d'itérations par tour (T2) est déterminé par la formule T2 = d/r, où d représente la dimension d'intégration et r désigne le rang utilisé dans SST.
\ \ 
\ \ \ 
\
F.4 Hyperparamètres des Réseaux de Neurones Graphiques Hyperboliques
Nous utilisons HyboNet [12] comme modèle de rang complet, avec les mêmes hyperparamètres que ceux utilisés dans HyboNet. Les expériences ont été menées sur un GPU A100.
\ Pour SST, le nombre d'étapes par itération (T3) est fixé à 100. Chaque itération commence par une phase de préchauffage durant 100 étapes. Le nombre d'itérations par tour (T2) est déterminé par la formule T2 = d/r, où d représente la dimension d'intégration et r désigne le rang utilisé dans SST.
\ Nous fixons le taux de dropout à 0,5 pour les méthodes LoRA et SST pendant la tâche de classification des nœuds sur le jeu de données Cora. C'est la seule déviation par rapport à la configuration HyboNet.
\ \ \
:::info Auteurs :
(1) Jialin Zhao, Centre d'Intelligence des Réseaux Complexes (CCNI), Laboratoire Tsinghua du Cerveau et de l'Intelligence (THBI) et Département d'Informatique ;
(2) Yingtao Zhang, Centre d'Intelligence des Réseaux Complexes (CCNI), Laboratoire Tsinghua du Cerveau et de l'Intelligence (THBI) et Département d'Informatique ;
(3) Xinghang Li, Département d'Informatique ;
(4) Huaping Liu, Département d'Informatique ;
(5) Carlo Vittorio Cannistraci, Centre d'Intelligence des Réseaux Complexes (CCNI), Laboratoire Tsinghua du Cerveau et de l'Intelligence (THBI), Département d'Informatique et Département de Génie Biomédical, Université Tsinghua, Pékin, Chine.
:::
:::info Cet article est disponible sur arxiv sous licence CC by 4.0 Deed (Attribution 4.0 International).
:::
\
Vous aimerez peut-être aussi

La liste des 15 Altcoins détenus par le plus grand nombre d'investisseurs a été publiée

Une Autre Entreprise Cotée au Nasdaq Annonce un Achat Massif de Bitcoin (BTC) ! Devient la 14e Plus Grande Entreprise ! – Ils Investiront Également dans une Altcoin Liée à Trump !
