

Comment les modèles d'IA hybrides équilibrent la mémoire et l'efficacité
Table des liens
Abstrait et 1. Introduction
-
Méthodologie
-
Expériences et Résultats
3.1 Modélisation du langage sur des données vQuality
3.2 Exploration sur l'attention et la récurrence linéaire
3.3 Extrapolation efficace de la longueur
3.4 Compréhension de contexte long
-
Analyse
-
Conclusion, Remerciements et Références
A. Détails d'implémentation
B. Résultats d'expériences supplémentaires
C. Détails de la mesure d'entropie
D. Limitations
\
A Détails d'implémentation
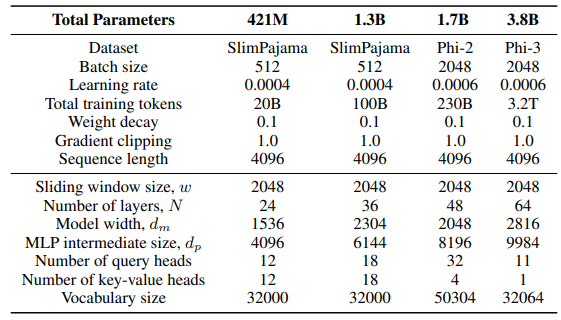
\ Pour la couche GLA dans l'architecture Sliding GLA, nous utilisons un nombre de têtes dm/384, un ratio d'expansion de clé de 0,5 et un ratio d'expansion de valeur de 1. Pour la couche RetNet, nous utilisons un nombre de têtes équivalent à la moitié du nombre de têtes de requête d'attention, un ratio d'expansion de clé de 1 et un ratio d'expansion de valeur de 2. Les implémentations de GLA et RetNet proviennent du dépôt Flash Linear Attention[3] [YZ24]. Nous utilisons l'implémentation basée sur FlashAttention pour l'extrapolation Self-Extend[4]. Le modèle Mamba 432M a une largeur de modèle de 1024 et le modèle Mamba 1.3B a une largeur de modèle de 2048. Tous les modèles entraînés sur SlimPajama ont les mêmes configurations d'entraînement et la taille intermédiaire MLP que Samba, sauf indication contraire. L'infrastructure d'entraînement sur SlimPajama est basée sur une version modifiée du code TinyLlama[5].
\ 
\ Dans les configurations de génération pour les tâches en aval, nous utilisons le décodage glouton pour GSM8K, et l'échantillonnage Nucleus [HBD+19] avec une température de τ = 0,2 et top-p = 0,95 pour HumanEval. Pour MBPP et SQuAD, nous définissons τ = 0,01 et top-p = 0,95.
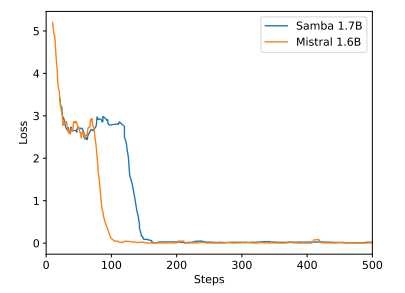
B Résultats d'expériences supplémentaires
\ 
\ 
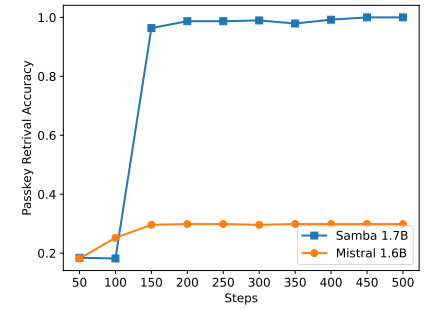
\ 
\
C Détails de la mesure d'entropie
\ 
\
D Limitations
Bien que Samba démontre des performances prometteuses de récupération de mémoire grâce à l'instruction tuning, son modèle de base pré-entraîné a des performances de récupération similaires à celles du modèle basé sur SWA, comme le montre la Figure 7. Cela ouvre une direction future pour améliorer davantage la capacité de récupération de Samba sans compromettre son efficacité et sa capacité d'extrapolation. De plus, la stratégie d'hybridation de Samba n'est pas systématiquement meilleure que les autres alternatives dans toutes les tâches. Comme le montre le Tableau 2, MambaSWA-MLP montre des performances améliorées sur des tâches telles que WinoGrande, SIQA et GSM8K. Cela nous donne le potentiel d'investir dans une approche plus sophistiquée pour effectuer des combinaisons dynamiques dépendantes de l'entrée des modèles basés sur SWA et SSM.
\
:::info Auteurs:
(1) Liliang Ren, Microsoft et University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Cet article est disponible sur arxiv sous licence CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
Vous aimerez peut-être aussi

Le token adossé à l'or de Tether dépasse les 2 milliards de dollars en capitalisation boursière
Truth Social Lance des Marchés de Prédiction Grâce à un Partenariat avec Crypto.com
