

Synthèse d'images médicales : S-CycleGAN pour RUSS et segmentation
Table des liens
Abstrait et 1 Introduction
-
Travaux connexes
-
Définition du problème
-
Méthodologie
4.1. Distillation consciente des limites de décision
4.2. Consolidation des connaissances
-
Résultats expérimentaux et 5.1. Configuration de l'expérience
5.2. Comparaison avec les méthodes de pointe
5.3. Étude d'ablation
-
Conclusion et travaux futurs et Références
\
Matériel supplémentaire
- Détails de l'analyse théorique du mécanisme KCEMA dans IIL
- Aperçu de l'algorithme
- Détails du jeu de données
- Détails d'implémentation
- Visualisation des images d'entrée poussiéreuses
- Plus de résultats expérimentaux
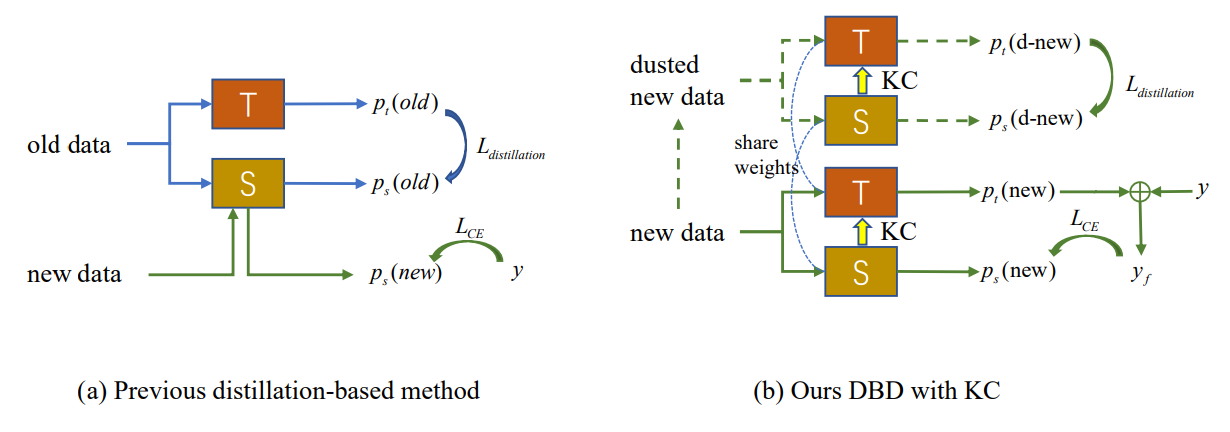
4. Méthodologie
Comme le montre la Fig. 2 (a), l'apparition d'une dérive conceptuelle dans les nouvelles observations conduit à l'émergence d'échantillons externes sur lesquels le modèle existant échoue. Le nouvel IIL doit élargir la limite de décision à ces échantillons externes tout en évitant l'oubli catastrophique (CF) sur l'ancienne limite. Les méthodes conventionnelles basées sur la distillation des connaissances s'appuient sur certains exemplaires préservés [22] ou des données auxiliaires [33, 34] pour résister au CF. Cependant, dans le cadre IIL proposé, nous n'avons accès à aucune ancienne donnée autre que les nouvelles observations. La distillation basée sur ces nouvelles observations entre en conflit avec l'apprentissage de nouvelles connaissances si aucun nouveau paramètre n'est ajouté au modèle. Pour trouver un équilibre entre l'apprentissage et la non-oubli, nous proposons une méthode de distillation consciente des limites de décision qui ne nécessite pas d'anciennes données. Pendant l'apprentissage, les nouvelles connaissances acquises par l'étudiant sont périodiquement consolidées dans le modèle de l'enseignant, ce qui apporte une meilleure généralisation et constitue une tentative pionnière dans ce domaine.
\ 
\
:::info Auteurs:
(1) Qiang Nie, Université des Sciences et Technologies de Hong Kong (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Université des Sciences et Technologies de Hong Kong (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Cet article est disponible sur arxiv sous la licence CC BY-NC-ND 4.0 Deed (Attribution-Pas d'Utilisation Commerciale-Pas de Modification 4.0 International).
:::
\
Vous aimerez peut-être aussi

Impasse sur la fermeture du gouvernement américain : les Marchés Crypto observent les impacts

Prédiction du Prix de Cronos : Peut-il Reconquérir 1$ Pendant qu'un Concurrent Caché en Prévente Devient la Meilleure Crypto dans Laquelle Investir en 2025 ?
