

Nouveau paramètre IIL : Amélioration des modèles déployés avec uniquement de nouvelles données
Table des liens
Abstrait et 1 Introduction
-
Travaux connexes
-
Définition du problème
-
Méthodologie
4.1. Distillation consciente des limites de décision
4.2. Consolidation des connaissances
-
Résultats expérimentaux et 5.1. Configuration de l'expérience
5.2. Comparaison avec les méthodes de pointe
5.3. Étude d'ablation
-
Conclusion et travaux futurs et Références
\
Matériel supplémentaire
- Détails de l'analyse théorique du mécanisme KCEMA dans IIL
- Aperçu de l'algorithme
- Détails du jeu de données
- Détails d'implémentation
- Visualisation des images d'entrée poussiéreuses
- Plus de résultats expérimentaux
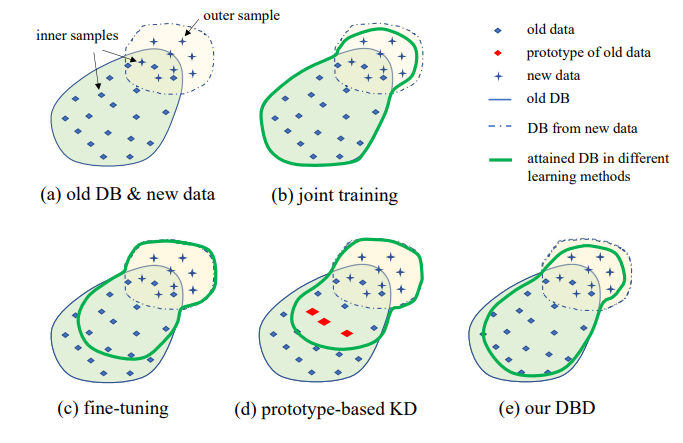
3. Définition du problème
L'illustration du paramètre IIL proposé est présentée dans la Fig. 1. Comme on peut le voir, les données sont générées continuellement et de manière imprévisible dans le flux de données. Généralement dans les applications réelles, les gens ont tendance à collecter d'abord suffisamment de données et à entraîner un modèle robuste M0 pour le déploiement. Peu importe la robustesse du modèle, il rencontrera inévitablement des données hors distribution et échouera sur celles-ci. Ces cas d'échec et d'autres nouvelles observations à faible score seront annotés pour entraîner le modèle de temps en temps. Réentraîner le modèle avec toutes les données cumulées à chaque fois entraîne des coûts de plus en plus élevés en temps et en ressources. Par conséquent, le nouvel IIL vise à améliorer le modèle existant avec uniquement les nouvelles données à chaque fois.
\ 
\ 
\
:::info Auteurs :
(1) Qiang Nie, Université des Sciences et Technologies de Hong Kong (Guangzhou) ;
(2) Weifu Fu, Tencent Youtu Lab ;
(3) Yuhuan Lin, Tencent Youtu Lab ;
(4) Jialin Li, Tencent Youtu Lab ;
(5) Yifeng Zhou, Tencent Youtu Lab ;
(6) Yong Liu, Tencent Youtu Lab ;
(7) Qiang Nie, Université des Sciences et Technologies de Hong Kong (Guangzhou) ;
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info Cet article est disponible sur arxiv sous licence CC BY-NC-ND 4.0 Deed (Attribution-Pas d'Utilisation Commerciale-Pas de Modification 4.0 International).
:::
\
Vous aimerez peut-être aussi

Reddit, Kick ajoutés à la liste noire croissante des réseaux sociaux pour adolescents en Australie

Ces Altcoins qui Encaissent Pendant que le Marché Chute : Voici les Projets Générant le Plus de Revenus
