

Enseigner à l'IA à voir et à parler : au cœur de l'approche OW-VISCap
Table des liens
Abstrait et 1. Introduction
-
Travaux connexes
2.1 Segmentation d'instances vidéo en monde ouvert
2.2 Légende dense d'objets vidéo et 2.3 Perte contrastive pour les requêtes d'objets
2.4 Compréhension vidéo généralisée et 2.5 Segmentation d'instances vidéo en monde fermé
-
Approche
3.1 Aperçu
3.2 Requêtes d'objets en monde ouvert
3.3 Tête de légende
3.4 Perte contrastive inter-requêtes et 3.5 Formation
-
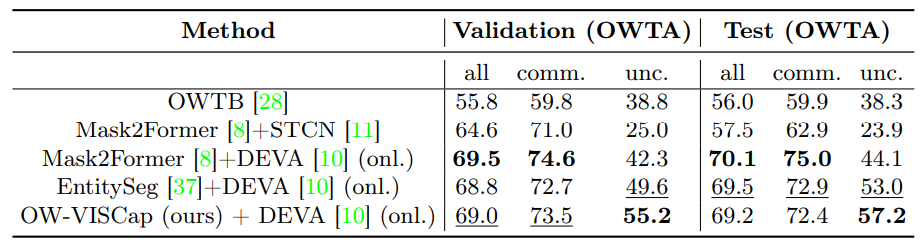
Expériences et 4.1 Ensembles de données et métriques d'évaluation
4.2 Résultats principaux
4.3 Études d'ablation et 4.4 Résultats qualitatifs
-
Conclusion, Remerciements et Références
\ Matériel supplémentaire
A. Analyse supplémentaire
B. Détails d'implémentation
C. Limitations
3 Approche
Étant donné une vidéo, notre objectif est de détecter, segmenter et légender conjointement les instances d'objets présentes dans la vidéo. Il est important de noter que les catégories d'instances d'objets peuvent ne pas faire partie de l'ensemble d'entraînement (par exemple, les parachutes montrés dans la Fig. 3 (rangée supérieure)), plaçant notre objectif dans un cadre de monde ouvert. Pour atteindre cet objectif, une vidéo donnée est d'abord divisée en courts clips, chacun composé de T images. Chaque clip est traité en utilisant notre approche OW-VISCap. Nous discutons de la fusion des résultats de chaque clip dans la Sec. 4.
\ Nous fournissons un aperçu d'OW-VISCap pour traiter chaque clip dans la Sec. 3.1. Nous discutons ensuite de nos contributions : (a) introduction de requêtes d'objets en monde ouvert dans la Sec. 3.2, (b) utilisation de l'attention masquée pour la légende centrée sur l'objet dans la Sec. 3.3, et (c) utilisation de la perte contrastive inter-requêtes pour garantir que les requêtes d'objets sont différentes les unes des autres dans la Sec. 3.4. Dans la Sec. 3.5, nous discutons de l'objectif final de formation.
3.1 Aperçu
\ Les requêtes d'objets en monde ouvert et fermé sont traitées par notre tête de légende spécifiquement conçue qui produit une légende centrée sur l'objet, une tête de classification qui produit une étiquette de catégorie, et une tête de détection qui produit soit un masque de segmentation, soit une boîte englobante.
\ 
\ Nous introduisons une perte contrastive inter-requêtes pour garantir que les requêtes d'objets sont encouragées à différer les unes des autres. Nous fournissons des détails dans la Sec. 3.4. Pour les objets du monde fermé, cette perte aide à éliminer les faux positifs hautement chevauchants. Pour les objets du monde ouvert, elle aide à la découverte de nouveaux objets.
\ Enfin, nous fournissons l'objectif complet de formation dans la Sec. 3.5.
\
3.2 Requêtes d'objets en monde ouvert
\ 
\ 
\ Nous faisons d'abord correspondre les objets de vérité terrain avec les prédictions du monde ouvert en minimisant un coût d'appariement à l'aide de l'algorithme hongrois [34]. L'appariement optimal est ensuite utilisé pour calculer la perte finale du monde ouvert.
\ 
\
3.3 Tête de légende
\ 
\
3.4 Perte contrastive inter-requêtes
\ 
\
3.5 Formation
Notre perte totale de formation est
\ 
\ ![Tableau 2: Résultats de légende dense d'objets vidéo sur l'ensemble de données VidSTG [57]. Off. indique les méthodes hors ligne et onl. fait référence aux méthodes en ligne.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Auteurs:
(1) Anwesa Choudhuri, Université de l'Illinois à Urbana-Champaign (anwesac2@illinois.edu);
(2) Girish Chowdhary, Université de l'Illinois à Urbana-Champaign (girishc@illinois.edu);
(3) Alexander G. Schwing, Université de l'Illinois à Urbana-Champaign (aschwing@illinois.edu).
:::
:::info Cet article est disponible sur arxiv sous licence CC by 4.0 Deed (Attribution 4.0 International).
:::
\
Vous aimerez peut-être aussi
Calendrier de l'Airdrop Flare : Chronologie complète des jetons FLR, éligibilité et processus de réclamation

Trust Wallet a lancé le programme de fidélité Trust Premium
