

Ottimizzazione dei Costi e dell'Utilizzo del Cluster Databricks Senza Tabelle di Sistema
Nella maggior parte degli ambienti Databricks aziendali (come in MSC o grandi ecosistemi analitici), le tabelle di sistema come system.job_run_logs o system.cluster_events potrebbero essere limitate o disabilitate a causa di politiche di sicurezza o governance.
Tuttavia, monitorare l'utilizzo e i costi del cluster è cruciale per:
- Comprendere quanto efficientemente i job utilizzano le risorse di calcolo
- Identificare cluster inattivi o perdite di costi
- Prevedere il budget dell'infrastruttura
- Costruire dashboard dei costi personalizzate
Questo blog dimostra un approccio passo dopo passo per calcolare l'utilizzo e i costi del cluster utilizzando solo le API REST di Databricks — senza tabelle di sistema richieste.
Caso d'uso del progetto
Nella nostra piattaforma dati MSC, eseguiamo molteplici cluster Databricks tra sviluppo, test e produzione. \n Abbiamo avuto tre sfide principali:
- Nessun accesso alle tabelle di sistema (limitato dalle politiche di amministrazione)
- Cluster effimeri per job creati dinamicamente da ADF o pipeline di orchestrazione
- Nessuna vista diretta di come l'utilizzo del cluster si traduce in costi
Pertanto, abbiamo costruito un analizzatore di utilizzo leggero che:
- Estrae dati dalle API REST di Databricks
- Calcola il runtime dei job rispetto al runtime del cluster
- Stima i costi utilizzando i tassi DBU e VM
- Genera un DataFrame facile da utilizzare
Il problema e l'approccio
La sfida identificata
I team hanno spesso bisogno di sapere:
- Quali cluster sono inattivi (in esecuzione con bassa attività dei job)?
- Qual è la percentuale di utilizzo (runtime dei job rispetto all'uptime del cluster)?
- Quanto costa ogni cluster (DBU + VM)?
Quando le tabelle di sistema di Unity Catalog (ad es., system.job_run_logs) non sono disponibili, l'approccio predefinito basato su SQL fallisce. L'API REST diventa l'alternativa affidabile.
Approccio di alto livello utilizzato nel notebook
- Elencare i cluster tramite /api/2.0/clusters/list.
- Stimare l'uptime del cluster utilizzando timestamp all'interno del JSON del cluster (campi created/start/terminated). (Questo è un fallback pragmatico quando /clusters/events non è disponibile.)
- Ottenere le esecuzioni recenti dei job utilizzando /api/2.1/jobs/runs/list con filtri temporali (o limite).
- Abbinare le esecuzioni dei job ai cluster utilizzando cluster_instance.cluster_id (o altri metadati del cluster).
- Calcolare l'utilizzo: % di utilizzo = total_job_runtime / total_cluster_uptime.
- Stimare i costi utilizzando una formula semplice: costo = running_hours × (DBU/hr × DBU assunti) + running_hours × nodi × VM $/hr.
Questo notebook utilizza intenzionalmente query delimitate (ultime N esecuzioni, finestra temporale) in modo che venga eseguito rapidamente.
\ 1. Configurazione e impostazione
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Questa sezione inizializza:
- URL del workspace e token di autenticazione
- Intervallo di tempo per il quale si desidera analizzare l'utilizzo
- Ipotesi sui costi:
- Tasso DBU ($/hr per DBU)
- Costo del nodo VM
- Consumo approssimativo di DBU
Nelle configurazioni aziendali, questi tassi possono essere recuperati dinamicamente tramite le tue API FinOps o di fatturazione.
-
Funzione wrapper API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Questa funzione helper standardizza tutte le chiamate GET dell'API REST. \n Essa:
-
Costruisce l'URL completo dell'endpoint
-
Gestisce il 404 in modo elegante (importante quando i cluster o le esecuzioni sono scaduti)
-
Restituisce JSON analizzato
Perché è importante: Questa funzione garantisce una comunicazione API pulita senza interrompere il flusso del notebook se mancano dati del cluster.
\
-
Elencare tutti i cluster attivi
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Questo recupera tutti i cluster disponibili nel tuo workspace. \n È equivalente a visualizzare la tua scheda "Compute" in modo programmatico. \n La risposta contiene:
-
ID dei cluster
-
Nomi
-
Numero di nodi
-
Informazioni sul creatore
-
Orari di creazione e terminazione
Caso d'uso: Aiuta a identificare quali cluster stanno consumando risorse nella finestra selezionata.
4. Stimare il runtime del cluster
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Calcoliamo le ore totali di esecuzione per ogni cluster:
-
Utilizza timestamp di creazione e terminazione
-
Gestisce i cluster attualmente in esecuzione (terminated_time mancante)
-
Normalizza in ore
Perché è importante: Questo valore è il denominatore per l'utilizzo — rappresenta l'uptime totale del cluster durante la finestra.
5. Ottenere le esecuzioni recenti dei job
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Invece di recuperare l'intera cronologia dei job (che è lenta), \n Questa funzione recupera le 10 esecuzioni di job più recenti per una diagnostica rapida.
In produzione, puoi filtrare per:
- job_id specifico
- completed_only=true
- Finestra temporale (start_time_from, start_time_to)
\
-
Calcolare l'utilizzo e i costi
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Questo è il cuore della logica:
-
Scorre ogni cluster
-
Calcola il runtime totale del job per cluster (utilizzando l'API delle esecuzioni dei job)
-
Deriva la percentuale di utilizzo = (job_hours / cluster_running_hours) × 100
-
Stima i costi:
- Costo DBU basato su tasso × DBU/hr
- Costo VM = node_count × node_cost/hr × running_hours
Perché è importante: \n Questo fornisce un quadro unificato di efficienza e spesa — utile per identificare cluster con costi elevati ma basso utilizzo.
7. Orchestrare la pipeline
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Questo blocco finale:
-
Recupera i dati
-
Esegue il calcolo dei costi
-
Visualizza il DataFrame ordinato
In pratica, questo DataFrame può essere:
-
Esportato in Excel o Delta Table
-
Inviato a dashboard Power BI
-
Integrato in pipeline di automazione FinOps
\
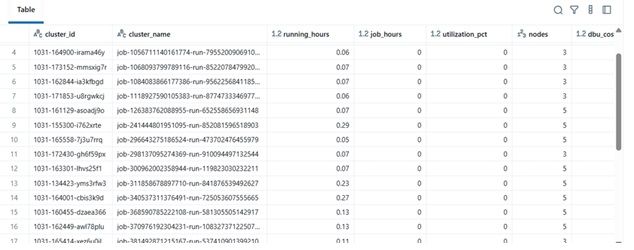
Esempio di risultati
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
Beneficio nel mondo reale
Implementando questo analizzatore:
-
I team di ingegneria possono monitorare i costi del cluster anche senza accesso all'audit.
-
I manager ottengono visibilità sui cluster sottoutilizzati.
-
DevOps può terminare automaticamente i cluster a basso utilizzo.
-
Il Finance può validare le fatture Databricks con metriche interne.
Nel nostro progetto MSC, lo abbiamo utilizzato come parte del nostro stack di osservabilità della piattaforma dati — combinando dati API REST, log dei job ADF e tendenze dei costi in una dashboard unificata.
\
Potrebbe anche piacerti

Nasdaq e CME Lanciano il Nuovo Nasdaq-CME Crypto Index—Una Svolta Epocale negli Asset Digitali

La Casa Bianca ha piani di riserva pronti se il tribunale blocca i dazi di Trump
