

Going From Reactive to Predictive Incident Response with AIOps
For a long time, the traditional incident-response model has been used to deal with crises, ranging from cybersecurity attacks to hardware and network failures. But times have changed, and we are now in a dynamic environment that has multi- and hybrid clouds with continuous-deploy pipelines. Those traditional models no longer work.
Today, systems generate countless events and thousands of metrics in a single sector. No wonder the reactive stance just doesn’t work anymore.
Well, the good news is that AIOps (Artificial Intelligence for IT Operations) is stepping up. In layman's terms, automated event correlation and machine learning drive operations not just to respond quicker but also to predict and remediate proactively. So, the future of incident response is going to be less about “we got another pager, let’s fix it” and more about “the user never notices because we anticipate and automatically act.”
1. Why Does Current Incident Response Fall Short?
\ 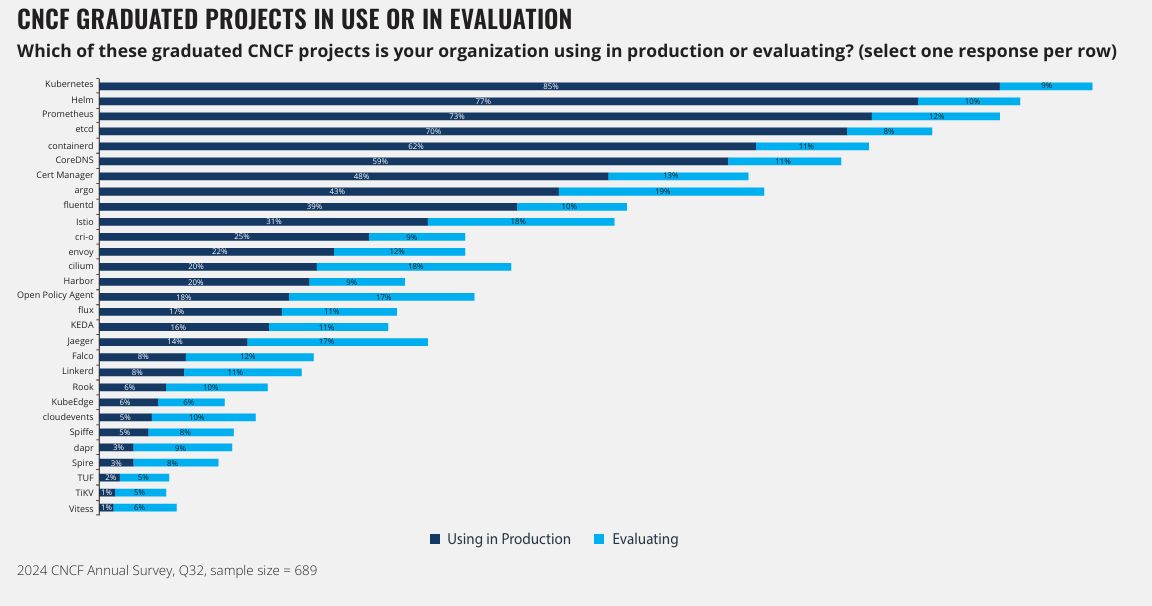
Before I talk about AIOps, it’s only fair to discuss the current shortfalls of traditional incident response. First of all, modern architecture has changed dramatically*.* We now run hundreds or even thousands of container-based services in multi-cloud and hybrid-cloud environments with changing topologies. For instance, CNCF (Cloud Native Computing Foundation) indicated in its 2024 survey that Kubernetes was used by 85% of firms in production (see Figure 1).
Additionally, 100-150 gigabytes (GB) of data per indexer is being ingested by enterprises daily, which collectively overwhelms legacy workflows.
Simply put, with multiple cloud environments and thousands of microservices, human processes cannot manage the size and velocity of operational data it generates. Second, the manual incident workflow is time-consuming. For instance, consider the steps: alert triggers a page → engineer logs in → inspects dashboards and traces → creates hypothesis → remediates everything manually. This increases Mean Time to Detect (MTTD) and Mean Time to Resolve (MTTR) of incidents for the operations team.
A study done by Pager Duty highlights that the average time it takes to manage an incident across 500 IT organizations is about 175 minutes, and it results in a downtime cost of about $4,500 per minute. So, obviously, this adds significant costs besides affecting customer experience. Moreover, in traditional incident responses, there is a lot of alert fatigue. For example, more than 10,000 alerts are processed daily by large organizations, and most of them are duplicates or false positives. DropZone study confirms that 66% of SOC teams cannot keep up with the pace of alerts. Additionally, 25-30% of alerts are even overlooked because of this overload.
2. Predictive Incident Response and AIOps in Practice
Sure, the current model for incident response is ineffective, but what about this predictive model? What do AIOps have for predictive incident responses? Let me explain by dividing it into three parts:
2.1 Machine Learning Based Observability and Anomaly Detection
At the very center of modern incident response is machine learning that is applied to observability data. This involves topology, events, traces, and even logs. This data is ingested into AIOps platforms and correlated across sources before possible anomalies and their root causes are identified. This is what helps with proactive actions.
There are multiple AIOps platforms that offer “Predictive Alerts.” Teams can use this feature to fit time-series models on historical metrics and predict future values (the next 360 observations). It will trigger an alert if a specific threshold may be breached in the future.
\
2.2 Policy-as-Code and Self-Healing Pipelines
It is surprising to learn that Site Reliability Engineering (SRE) teams are codifying their remediation and reliability policies as executable codes. For instance, Service Level Objectives (SLOs) and roll-back rules are defined, and when they are combined with an AIOps engine that found a risk, the system can remediate automatically. For example, it can roll back a canary deployment that is seen as risky or even scale up a microservice prior to a forecasted increase.
Moreover, in a platform like Kubernetes, this can be implemented using custom operators that can monitor reliability metrics and perform actions. For example: traffic routing by an operator when a threshold is breached for an error-budget rate. In academic studies, many authors like Zota et al. (2025) see autonomous agents as carrying out end-to-end operations across incident lifecycles.
2.3 SLO Led Automation and Error-Budget Enforcement
Many organizations now have SLOs, and error budgets (EB) integrated into their real-time operations, not just in dashboards. When an upcoming SLO breach is predicted by an AIOps engine, mitigations can be started automatically by the system. For instance, it can spin up additional resources or pause a rollout. This will save a lot of hassle in terms of decision-making and manual work.
In the industry, open-source stacks such as Prometheus for collecting metrics and Grafana for dashboards are commonly used. In fact, they form the base of ingestion for machine learning (ML) pipelines. Data collected by Prometheus becomes the input for ML models, which is assessed to find patterns and forecast future incidents. Meanwhile, these predictions are visualized by Grafana.
2.4 Benefits of Predictive Incident Response
So, what would happen if businesses switched to predictive and automated incident responses?
Both MTTD and MTTR will decrease significantly. When anomaly detection and automation are combined, detection becomes quicker. Research done by Purushotham Reddy (2021) on the AWS platform confirms that predefined playbooks and automation decreased MTTD by 62% and MTTR by 51%. This means a decrease from 97 minutes to 37 minutes in MTTD and 4.3 hours to 2.1 hours in MTTR. The main benefit is clear: firms experience less downtime and less revenue loss due to faster recovery.
Another benefit is that the operational toil has decreased. By automating incident categorization and alert correlation, DevOps engineers and SREs can focus on proactive work. An article on CNBC confirms that AIOps can reduce burnout, which means happier teams and less turnover.
The key benefits that integration of AIOps into operations provides are reduced downtime, improved availability, and stability of the systems. There are many factors contributing to this; such as scaling services proactively before a forecasted load increase and routing traffic during performance degradation, resulting in fewer incidents and better availability. This availability improvement directly enhances customer experience as they do not have to wait and can seamlessly carry out their interactions without any disruptions.
3. Architecture Flowchart
Figure 2 shows an architecture flowchart for predictive incident response in an AIOps environment:
4. Implementation Considerations and Best Practices
AIOps provides significant benefits in predictive operations. However, there are trade-offs to consider. Here are key best practices:
4.1 Data Quality and Ingestion
Many organizations fail to recognize the importance of telemetry, even though everything from models to automation relies on high-quality and timely data. That is why it is important for companies to invest in pipelines that can ingest change events, metrics, logs, traces, labels to enrich them. Motadata reports that over 65% of failures in AIOps are caused by poor ingestion of data.
Therefore, the best practice is to begin with smaller domains, such as a key service where data is manageable. After cleaning the data, build models and then expand as you deem right.
4.2 Phased Adoption
There is no need to target a “full self-heading system.” Many firms succeed in using a phased approach. So, instead, focus on three key phases:
- Improving visibility and triage automation, such as reducing alert noise and correlating events.
- Enabling automatic diagnosis and recommendations through machine learning.
Allowing self-healing and continuous learning through agents.
As per the industry standard, it takes about 12-18 months to move from Phase 1 to Phase 3, so focus on building trust along the way.
4.3 Governance and Explainability
Many organizations make the mistake of removing human governance altogether from an AIOps system. Until trust is built, keep humans in the loop. After all, model transparency and clear Service Level Agreements (SLAs) for automation of decisions are important. A best practice is to document the reasons for remediation and enable engineers to feed results back into the system for retraining.
4.4 Skills and Metrics
Reliability engineering teams need to evolve from traditional SRE skills and develop expertise in DevOps tooling and automation. Businesses must create a culture to improve training and cross-functional collaboration. A best practice is to invest in training and create cross-functional teams to ensure shared understanding.
Track the key metrics, including MTTD, MTTR, alert volume, reduced toil hours, and cost of downtime before and after the implementation of AIOps to see the value.
Conclusion
The shift from reactive incident response to self-healing operations is now essential for businesses. Modern systems are too complex to be managed by legacy workflows. Therefore, firms need to adopt a mindset of “we prevented it from breaking” by investing in telemetry, applying machine learning and automation, and ensuring a culture of continuous improvement.
You May Also Like

Ethereum unveils roadmap focusing on scaling, interoperability, and security at Japan Dev Conference


XRP price sees bearish divergence despite DEX volume surge
