

Visual Prompt Generators (VPGs): Encoding Images to LLM Tokens
Table of Links
Abstract and 1 Introduction
-
Related Work
2.1. Multimodal Learning
2.2. Multiple Instance Learning
-
Methodology
3.1. Preliminaries and Notations
3.2. Relations between Attention-based VPG and MIL
3.3. MIVPG for Multiple Visual Inputs
3.4. Unveiling Instance Correlation in MIVPG for Enhanced Multi-instance Scenarios
-
Experiments and 4.1. General Setup
4.2. Scenario 1: Samples with Single Image
4.3. Scenario 2: Samples with Multiple Images, with Each Image as a General Embedding
4.4. Scenario 3: Samples with Multiple Images, with Each Image Having Multiple Patches to be Considered and 4.5. Case Study
-
Conclusion and References
\ Supplementary Material
A. Detailed Architecture of QFormer
B. Proof of Proposition
C. More Experiments
3. Methodology
3.1. Preliminaries and Notations
\ 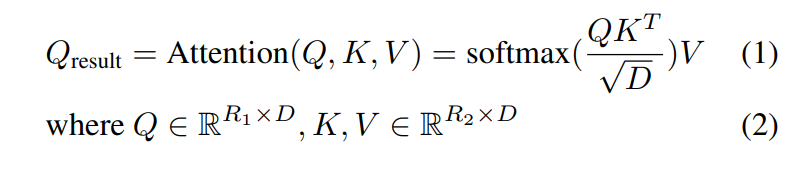
\ 
\ 
\
:::info Authors:
(1) Wenliang Zhong, The University of Texas at Arlington (wxz9204@mavs.uta.edu);
(2) Wenyi Wu, Amazon (wenyiwu@amazon.com);
(3) Qi Li, Amazon (qlimz@amazon.com);
(4) Rob Barton, Amazon (rab@amazon.com);
(5) Boxin Du, Amazon (boxin@amazon.com);
(6) Shioulin Sam, Amazon (shioulin@amazon.com);
(7) Karim Bouyarmane, Amazon (bouykari@amazon.com);
(8) Ismail Tutar, Amazon (ismailt@amazon.com);
(9) Junzhou Huang, The University of Texas at Arlington (jzhuang@uta.edu).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

Russia’s Central Bank Prepares Crackdown on Crypto in New 2026–2028 Strategy

According to Market Analysts This $0.012 AI Token Could Be the Best Investment of the Decade — Ozak AI’s 41,000% Potential Outshines Ethereum’s Early Growth
