

Технические детали: обучение BSGAL, основа Swin-L и стратегия динамического порога
Таблица ссылок
Резюме и 1 Введение
-
Связанные работы
2.1. Генеративное расширение данных
2.2. Активное обучение и анализ данных
-
Предварительная информация
-
Наш метод
4.1. Оценка вклада в идеальном сценарии
4.2. Пакетное потоковое генеративное активное обучение
-
Эксперименты и 5.1. Офлайн-настройка
5.2. Онлайн-настройка
-
Заключение, более широкое влияние и ссылки
\
A. Детали реализации
B. Дополнительные исследования
C. Обсуждение
D. Визуализация
A. Детали реализации
A.1. Набор данных
Мы выбрали LVIS (Gupta et al., 2019) в качестве набора данных для наших экспериментов. LVIS - это масштабный набор данных сегментации экземпляров, включающий примерно 160 000 изображений с более чем 2 миллионами высококачественных аннотаций сегментации экземпляров по 1203 категориям реального мира. Набор данных дополнительно разделен на три категории: редкие, обычные и частые, в зависимости от их встречаемости на изображениях. Экземпляры, помеченные как "редкие", встречаются в 1-10 изображениях, "обычные" экземпляры встречаются в 11-100 изображениях, тогда как "частые" экземпляры встречаются более чем в 100 изображениях. Общий набор данных демонстрирует распределение с длинным хвостом, близко напоминающее распределение данных в реальном мире, и широко применяется в различных условиях, включая сегментацию с малым количеством примеров (Liu et al., 2023) и сегментацию открытого мира (Wang et al., 2022; Zhu et al., 2023). Поэтому мы считаем, что выбор LVIS позволяет лучше отразить производительность модели в реальных сценариях. Мы используем официальное разделение набора данных LVIS, с примерно 100 000 изображений в обучающем наборе и 20 000 изображений в валидационном наборе.
A.2. Генерация данных
Наш процесс генерации данных и аннотирования соответствует Zhao et al. (2023), и мы кратко представляем его здесь. Сначала мы используем StableDiffusion V1.5 (Rombach et al., 2022a) (SD) в качестве генеративной модели. Для 1203 категорий в LVIS (Gupta et al., 2019) мы генерируем 1000 изображений на категорию с разрешением изображения 512 × 512. Шаблон запроса для генерации - "a photo of a single {CATEGORY NAME}". Мы используем U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023) и CLIPseg (Luddecke and Ecker, 2022) соответственно для аннотирования сырых генеративных изображений и выбираем маску с наивысшим показателем CLIP в качестве окончательной аннотации. Для обеспечения качества данных изображения с показателями CLIP ниже 0.21 отфильтровываются как изображения низкого качества. Во время обучения мы также используем стратегию вставки экземпляров, предоставленную Zhao et al. (2023) для расширения данных. Для каждого экземпляра мы случайным образом изменяем его размер, чтобы соответствовать распределению его категории в обучающем наборе. Максимальное количество вставленных экземпляров на изображение установлено на 20.
\ Кроме того, чтобы дополнительно расширить разнообразие сгенерированных данных и сделать наше исследование более универсальным, мы также используем другие генеративные модели, включая DeepFloyd-IF (Shonenkov et al., 2023) (IF) и Perfusion (Tewel et al., 2023) (PER), с 500 изображениями на категорию на модель. Для IF мы используем предварительно обученную модель, предоставленную автором, и сгенерированные изображения являются выходом Stage II с разрешением 256×256. Для PER базовая модель, которую мы используем, - это StableDiffusion V1.5. Для каждой категории мы дообучаем модель, используя изображения, вырезанные из обучающего набора, с 400 шагами дообучения. Мы используем дообученную модель для генерации изображений.
\ 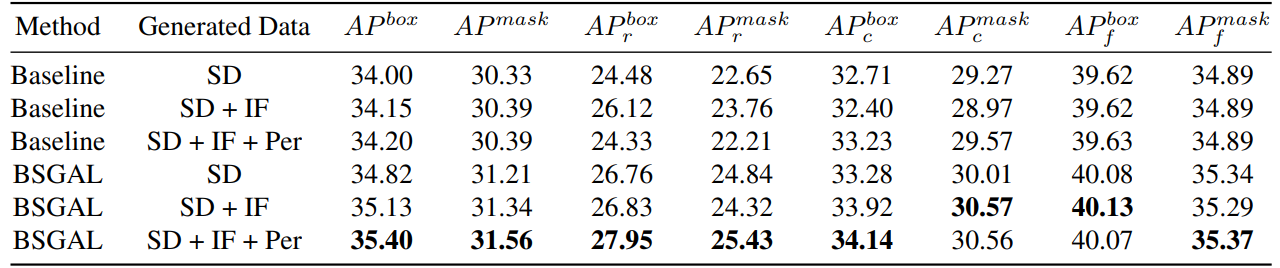
\ Мы также исследуем влияние использования различных сгенерированных данных на производительность модели (см. Таблицу 7). Мы видим, что на основе оригинального StableDiffusion V1.5 использование других генеративных моделей может принести некоторое улучшение производительности, но это улучшение не очевидно. В частности, для конкретных категорий частоты мы обнаружили, что IF имеет более значительное улучшение для редких категорий, в то время как PER имеет более значительное улучшение для обычных категорий. Это, вероятно, потому что данные IF более разнообразны, в то время как данные PER более соответствуют распределению обучающего набора. Учитывая, что общая производительность была улучшена до определенной степени, мы в итоге принимаем сгенерированные данные SD + IF + PER для последующих экспериментов.
A.3. Обучение модели
Следуя Zhao et al. (2023), мы используем CenterNet2 (Zhou et al., 2021) в качестве нашей модели сегментации, с ResNet-50 (He et al., 2016) или Swin-L (Liu et al., 2022) в качестве основы. Для ResNet-50 максимальное количество итераций обучения установлено на 90 000, и модель инициализируется весами, сначала предварительно обученными на ImageNet-22k, а затем дообученными на LVIS (Gupta et al., 2019), как это сделали Zhao
\ 
\ et al. (2023). И мы используем 4 GPU Nvidia 4090 с размером пакета 16 во время обучения. Что касается Swin-L, максимальное количество итераций обучения установлено на 180 000, и модель инициализируется весами, предварительно обученными на ImageNet-22k, поскольку наши ранние эксперименты показывают, что эта инициализация может принести небольшое улучшение по сравнению с весами, обученными с LVIS. И мы используем 4 GPU Nvidia A100 с размером пакета 16 для обучения. Кроме того, из-за большого количества параметров Swin-L дополнительная память, занимаемая сохранением градиента, велика, поэтому мы фактически используем алгоритм в Алгоритме 2.
\ Другие неуказанные параметры также следуют тем же настройкам, что и X-Paste (Zhao et al., 2023), таким как оптимизатор AdamW (Loshchilov and Hutter, 2017) с начальной скоростью обучения 1e−4.
A.4. Количество данных
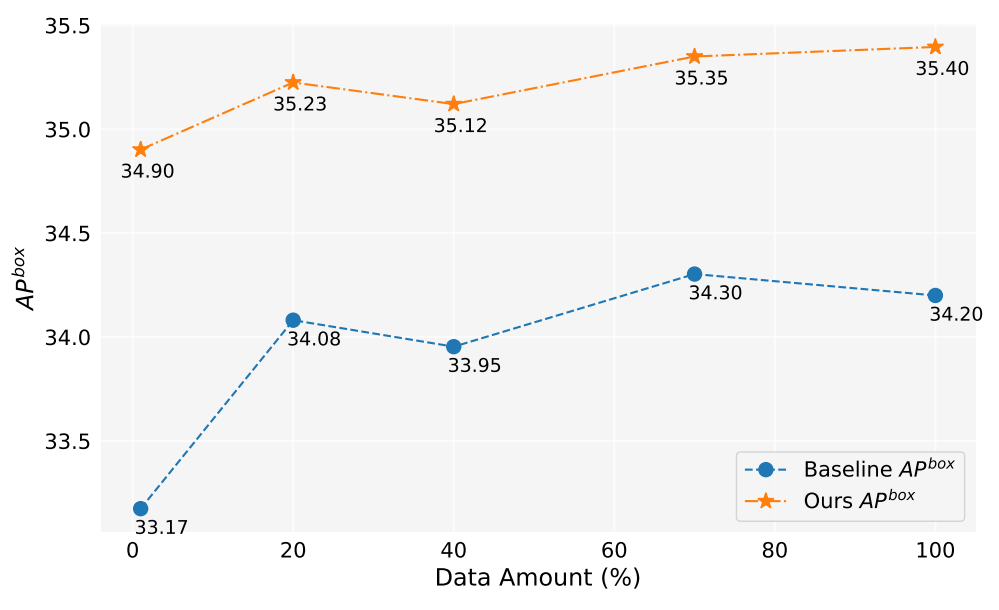
В этой работе мы сгенерировали более 2 миллионов изображений. Рисунок 5 показывает производительность модели при использовании различного количества сгенерированных данных (1%, 10%, 40%, 70%, 100%). В целом, по мере увеличения количества сгенерированных данных производительность модели также улучшается, но также наблюдаются некоторые колебания. Наш метод всегда лучше базового, что доказывает эффективность и надежность нашего метода.
A.5. Оценка вклада
\ Таким образом, мы по существу вычисляем косинусное сходство. Затем мы провели экспериментальное сравнение, как показано в Таблице 8,
\ 
\ 
\ мы можем видеть, что если мы нормализуем градиент, наш метод будет иметь определенное улучшение. Кроме того, поскольку нам нужно поддерживать два разных порога, трудно обеспечить согласованность коэффициента принятия. Поэтому мы принимаем стратегию динамического порога, предварительно устанавливаем коэффициент принятия, поддерживаем очередь для сохранения вклада предыдущей итерации, а затем динамически корректируем порог в соответствии с очередью, так что коэффициент принятия остается на предварительно установленном уровне.
A.6. Игрушечный эксперимент
Ниже приведены конкретные экспериментальные настройки, реализованные на CIFAR-10: мы использовали простой ResNet18 в качестве базовой модели и провели обучение в течение 200 эпох, и точность после обучения на оригинальном обучающем наборе составляет 93.02%. Скорость обучения установлена на 0.1, используя оптимизатор SGD. Действует момент 0.9 с весовым распадом 5e-4. Мы используем планировщик скорости обучения с косинусным затуханием. Сконструированные шумные изображения изображены на Рисунке 6. Наблюдается снижение качества изображения по мере увеличения уровня шума. Примечательно, что когда уровень шума достигает 200, изображения становятся значительно сложными для идентификации. Для Таблицы 1 мы используем Split1 как R, в то время как G состоит из 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Упрощение только один раз вперед
\
:::info Авторы:
(1) Muzhi Zhu, с равным вкладом из Чжэцзянского университета, Китай;
(2) Chengxiang Fan, с равным вкладом из Чжэцзянского университета, Китай;
(3) Hao Chen, Чжэцзянский университет, Китай (haochen.cad@zju.edu.cn);
(4) Yang Liu, Чжэцзянский университет, Китай;
(5) Weian Mao, Чжэцзянский университет, Китай и Университет Аделаиды, Австралия;
(6) Xiaogang Xu, Чжэцзянский университет, Китай;
(7) Chunhua Shen, Чжэцзянский университет, Китай (chunhuashen@zju.edu.cn).
:::
:::info Эта статья доступна на arxiv под лицензией CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Вам также может быть интересно

21 DAO и Tilted объединяются для развития более умной цифровой экономики на базе ИИ в Web3

Председатель SEC прогнозирует, что Bitcoin станет основой глобальной финансовой системы на фоне криптовалютной трансформации
