

Технічні деталі: навчання BSGAL, основа Swin-L та стратегія динамічного порогу
Таблиця посилань
Анотація та 1 Вступ
-
Пов'язані роботи
2.1. Генеративне розширення даних
2.2. Активне навчання та аналіз даних
-
Попередні відомості
-
Наш метод
4.1. Оцінка внеску в ідеальному сценарії
4.2. Пакетне потокове генеративне активне навчання
-
Експерименти та 5.1. Офлайн-налаштування
5.2. Онлайн-налаштування
-
Висновок, ширший вплив та посилання
\
A. Деталі реалізації
B. Більше аблацій
C. Обговорення
D. Візуалізація
A. Деталі реалізації
A.1. Набір даних
Ми обрали LVIS (Gupta et al., 2019) як набір даних для наших експериментів. LVIS - це масштабний набір даних сегментації екземплярів, що містить приблизно 160 000 зображень з понад 2 мільйонами високоякісних анотацій сегментації екземплярів у 1203 категоріях реального світу. Набір даних додатково поділений на три категорії: рідкісні, звичайні та часті, залежно від їх появи на зображеннях. Екземпляри, позначені як "рідкісні", з'являються на 1-10 зображеннях, "звичайні" екземпляри з'являються на 11-100 зображеннях, тоді як "часті" екземпляри з'являються на більш ніж 100 зображеннях. Загальний набір даних демонструє розподіл з довгим хвостом, що тісно нагадує розподіл даних у реальному світі, і широко застосовується в різних налаштуваннях, включаючи сегментацію з малою кількістю прикладів (Liu et al., 2023) та сегментацію відкритого світу (Wang et al., 2022; Zhu et al., 2023). Тому ми вважаємо, що вибір LVIS дозволяє краще відобразити продуктивність моделі в реальних сценаріях. Ми використовуємо офіційні розділи набору даних LVIS, з приблизно 100 000 зображень у навчальному наборі та 20 000 зображень у валідаційному наборі.
A.2. Генерація даних
Наш процес генерації та анотації даних відповідає Zhao et al. (2023), і ми коротко представляємо його тут. Спочатку ми використовуємо StableDiffusion V1.5 (Rombach et al., 2022a) (SD) як генеративну модель. Для 1203 категорій у LVIS (Gupta et al., 2019) ми генеруємо 1000 зображень на категорію з роздільною здатністю зображення 512 × 512. Шаблон підказки для генерації - "a photo of a single {CATEGORY NAME}". Ми використовуємо U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023) та CLIPseg (Luddecke and Ecker, 2022) відповідно для анотації необроблених генеративних зображень і вибираємо маску з найвищим показником CLIP як остаточну анотацію. Для забезпечення якості даних зображення з показниками CLIP нижче 0,21 відфільтровуються як низькоякісні зображення. Під час навчання ми також використовуємо стратегію вставки екземплярів, надану Zhao et al. (2023) для розширення даних. Для кожного екземпляра ми випадковим чином змінюємо його розмір, щоб відповідати розподілу його категорії в навчальному наборі. Максимальна кількість вставлених екземплярів на зображення встановлена на 20.
\ Крім того, щоб додатково розширити різноманітність генерованих даних і зробити наше дослідження більш універсальним, ми також використовуємо інші генеративні моделі, включаючи DeepFloyd-IF (Shonenkov et al., 2023) (IF) та Perfusion (Tewel et al., 2023) (PER), з 500 зображеннями на категорію на модель. Для IF ми використовуємо попередньо навчену модель, надану автором, і згенеровані зображення є виходом Stage II з роздільною здатністю 256×256. Для PER базова модель, яку ми використовуємо, - це StableDiffusion V1.5. Для кожної категорії ми точно налаштовуємо модель, використовуючи зображення, вирізані з навчального набору, з 400 кроками точного налаштування. Ми використовуємо точно налаштовану модель для генерації зображень.
\ 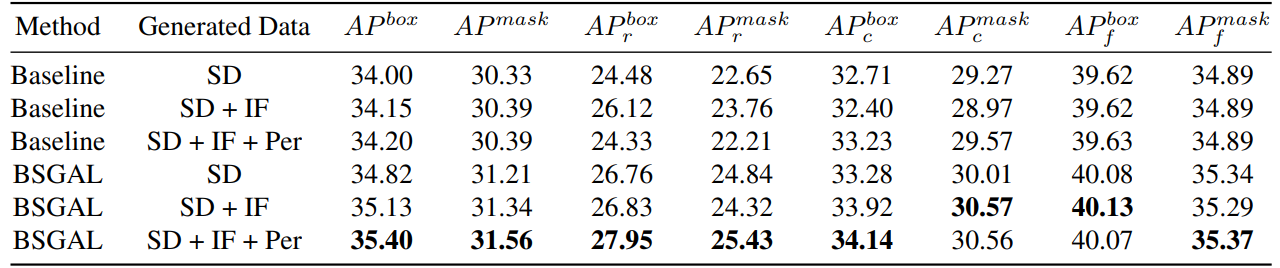
\ Ми також досліджуємо вплив використання різних генерованих даних на продуктивність моделі (див. Таблицю 7). Ми можемо бачити, що на основі оригінального StableDiffusion V1.5 використання інших генеративних моделей може принести деяке покращення продуктивності, але це покращення не є очевидним. Зокрема, для конкретних категорій частоти ми виявили, що IF має більш значне покращення для рідкісних категорій, тоді як PER має більш значне покращення для звичайних категорій. Це, ймовірно, тому, що дані IF більш різноманітні, тоді як дані PER більш відповідають розподілу навчального набору. Враховуючи, що загальна продуктивність була покращена до певної міри, ми нарешті приймаємо генеровані дані SD + IF + PER для подальших експериментів.
A.3. Навчання моделі
Слідуючи Zhao et al. (2023), ми використовуємо CenterNet2 (Zhou et al., 2021) як нашу модель сегментації, з ResNet-50 (He et al., 2016) або Swin-L (Liu et al., 2022) як основу. Для ResNet-50 максимальна кількість ітерацій навчання встановлена на 90 000, і модель ініціалізується вагами, спочатку попередньо навченими на ImageNet-22k, а потім точно налаштованими на LVIS (Gupta et al., 2019), як це зробили Zhao
\ 
\ et al. (2023). І ми використовуємо 4 графічні процесори Nvidia 4090 з розміром пакету 16 під час навчання. Що стосується Swin-L, максимальна кількість ітерацій навчання встановлена на 180 000, і модель ініціалізується вагами, попередньо навченими на ImageNet-22k, оскільки наші ранні експерименти показують, що ця ініціалізація може принести невелике покращення порівняно з вагами, навченими з LVIS. І ми використовуємо 4 графічні процесори Nvidia A100 з розміром пакету 16 для навчання. Крім того, через велику кількість параметрів Swin-L, додаткова пам'ять, зайнята збереженням градієнта, велика, тому ми фактично використовуємо алгоритм в Алгоритмі 2.
\ Інші невказані параметри також відповідають тим самим налаштуванням, що і X-Paste (Zhao et al., 2023), таким як оптимізатор AdamW (Loshchilov and Hutter, 2017) з початковою швидкістю навчання 1e−4.
A.4. Кількість даних
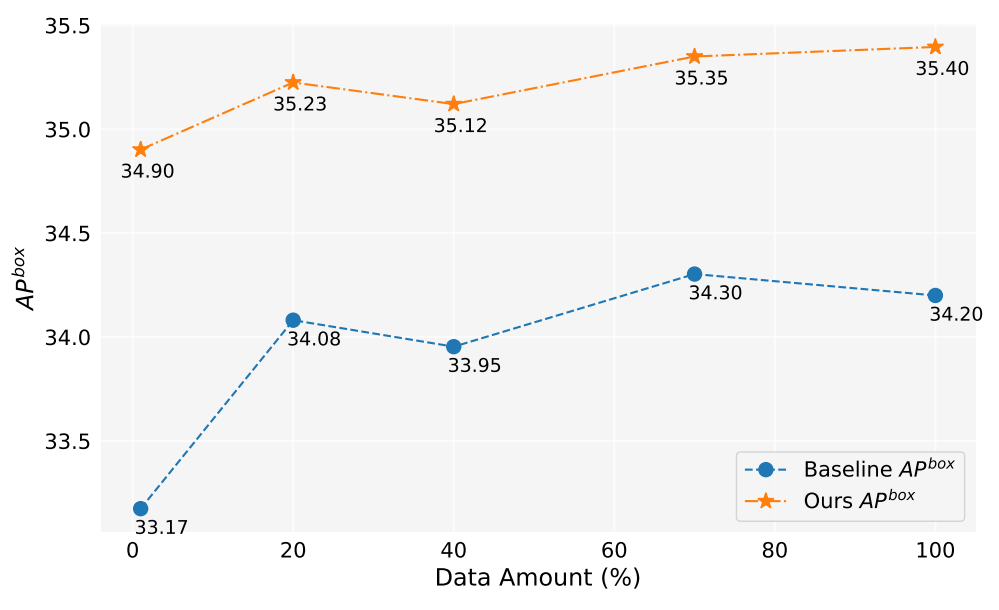
У цій роботі ми згенерували понад 2 мільйони зображень. Рисунок 5 показує продуктивність моделі при використанні різної кількості генерованих даних (1%, 10%, 40%, 70%, 100%). Загалом, зі збільшенням кількості генерованих даних продуктивність моделі також покращується, але також є деякі коливання. Наш метод завжди кращий за базовий, що доводить ефективність і надійність нашого методу.
A.5. Оцінка внеску
\ Таким чином, ми по суті обчислюємо косинусну подібність. Потім ми провели експериментальне порівняння, як показано в Таблиці 8,
\ 
\ 
\ ми можемо бачити, що якщо ми нормалізуємо градієнт, наш метод матиме певне покращення. Крім того, оскільки нам потрібно зберігати два різні пороги, важко забезпечити узгодженість швидкості прийняття. Тому ми приймаємо стратегію динамічного порогу, попередньо встановлюємо швидкість прийняття, підтримуємо чергу для збереження внеску попередньої ітерації, а потім динамічно регулюємо поріг відповідно до черги, щоб швидкість прийняття залишалася на попередньо встановленій швидкості прийняття.
A.6. Іграшковий експеримент
Нижче наведені конкретні експериментальні налаштування, реалізовані на CIFAR-10: ми використовували простий ResNet18 як базову модель і провели навчання протягом 200 епох, і точність після навчання на оригінальному навчальному наборі становить 93,02%. Швидкість навчання встановлена на 0,1, використовуючи оптимізатор SGD. Діє імпульс 0,9 з вагою розпаду 5e-4. Ми використовуємо планувальник швидкості навчання з косинусним згасанням. Сконструйовані шумні зображення зображені на Рисунку 6. Спостерігається зниження якості зображення зі збільшенням рівня шуму. Зокрема, коли рівень шуму досягає 200, зображення стають значно складними для ідентифікації. Для Таблиці 1 ми використовуємо Split1 як R, тоді як G складається з 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Спрощення лише один раз вперед
\
:::info Автори:
(1) Muzhi Zhu, з рівним внеском від Zhejiang University, Китай;
(2) Chengxiang Fan, з рівним внеском від Zhejiang University, Китай;
(3) Hao Chen, Zhejiang University, Китай (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, Китай;
(5) Weian Mao, Zhejiang University, Китай та The University of Adelaide, Австралія;
(6) Xiaogang Xu, Zhejiang University, Китай;
(7) Chunhua Shen, Zhejiang University, Китай (chunhuashen@zju.edu.cn).
:::
:::info Ця стаття доступна на arxiv під ліцензією CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Вам також може сподобатися

Голова Комісії з цінних паперів і бірж США: Вся фінансова система перейде на Bitcoin та криптовалюти протягом кількох років.
