

使用自适应批处理使您的数据管道速度提高5倍
您的数据转换流程中是否有大量的LLM调用?
CocoIndex可能能够帮助您。它由超高性能的Rust引擎提供支持,现在开箱即支持自适应批处理。这为AI原生工作流提高了约5倍的吞吐量(运行时间快约80%)。最重要的是,您无需更改任何代码,因为批处理会自动进行,适应您的流量并保持GPU充分利用。
以下是我们在为Cocoindex构建自适应批处理支持时学到的内容。
但首先,让我们回答一些您可能想知道的问题。
为什么批处理能加速处理?
-
每次调用的固定开销:这包括在实际计算开始前所需的所有准备和管理工作。例如GPU内核启动设置、Python到C/C++的转换、任务调度、内存分配和管理,以及框架执行的记账工作。这些开销任务在很大程度上与输入大小无关,但每次调用都必须全额支付。
\
-
数据依赖工作:计算的这部分直接随输入的大小和复杂性而扩展。它包括模型执行的浮点运算(FLOPs)、跨内存层次结构的数据移动、令牌处理和其他特定于输入的操作。与固定开销不同,这种成本与处理的数据量成正比增加。
当项目被单独处理时,每个项目都会重复产生固定开销,这可能会迅速主导总运行时间,特别是当每项计算相对较小时。相比之下,批量处理多个项目可以显著减少每项的开销影响。批处理允许将固定成本分摊到多个项目上,同时还能启用硬件和软件优化,提高数据依赖工作的效率。这些优化包括更有效地利用GPU管道、更好的缓存利用率和更少的内核启动,所有这些都有助于提高吞吐量并降低整体延迟。
\
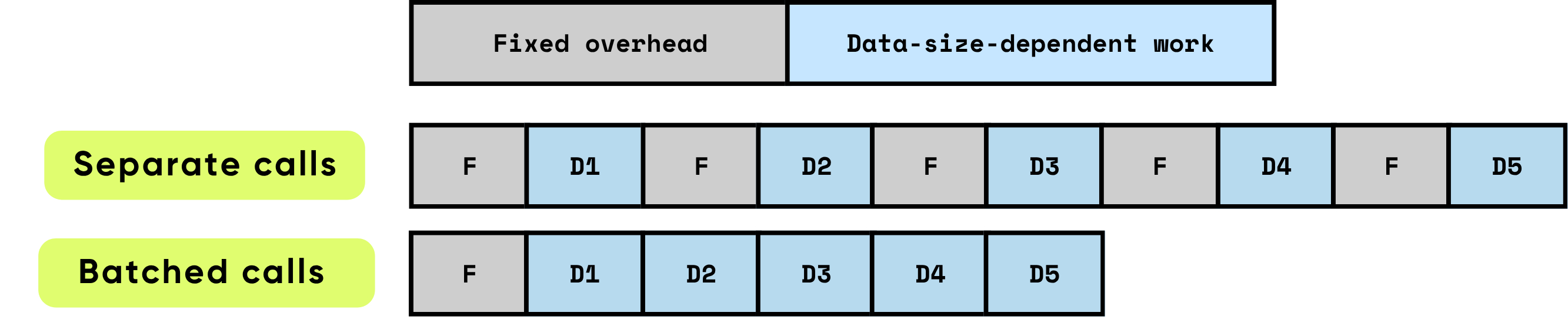
\ 批处理通过优化计算效率和资源利用率显著提高性能。它提供多种叠加的好处:
\
-
分摊一次性开销:每个函数或API调用都带有固定开销 — GPU内核启动、Python到C/C++转换、任务调度、内存管理和框架记账。通过批量处理项目,这种开销分散到多个输入上,大幅降低每项成本并消除重复的设置工作。
\
-
最大化GPU效率:更大的批次允许GPU以密集、高度并行的矩阵乘法形式执行操作,通常实现为通用矩阵-矩阵乘法(GEMM)。这种映射确保硬件以更高的利用率运行,充分利用并行计算单元,最小化空闲周期,并实现峰值吞吐量。小型、非批处理操作会使GPU大部分处于未充分利用状态,浪费昂贵的计算能力。
\
-
减少数据传输开销:批处理最小化CPU(主机)和GPU(设备)之间的内存传输频率。更少的主机到设备(H2D)和设备到主机(D2H)操作意味着减少数据移动时间,更多时间用于实际计算。这对高吞吐量系统至关重要,因为内存带宽通常成为限制因素,而非原始计算能力。
结合起来,这些效果导致吞吐量提高数个数量级。批处理将许多小型、低效的计算转变为大型、高度优化的操作,充分利用现代硬件能力。对于AI工作负载 — 包括大型语言模型、计算机视觉和实时数据处理 — 批处理不仅是一种优化;它对于实现可扩展的生产级性能至关重要。
\
普通Python代码的批处理是什么样的
非批处理代码 – 简单但效率较低
组织管道最自然的方式是逐个处理数据。例如,像这样的两层循环:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
这很容易阅读和理解:每个块直接流经多个步骤。
手动批处理 – 更高效但更复杂
您可以通过批处理加速它,但即使是最简单的"一次批处理所有内容"版本也会使代码变得更加复杂:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
此外,一次批处理所有内容通常不是理想的,因为下一步只能在所有数据完成此步骤后才能开始。
CocoIndex的批处理支持
CocoIndex弥合了差距,让您能够两全其美 – 通过遵循自然流程保持代码的简单性,同时获得CocoIndex运行时提供的批处理效率。
我们已经为以下内置函数启用了批处理支持:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
它不会改变API。您现有的代码无需任何更改即可工作 – 仍然遵循自然流程,同时享受批处理的效率。
对于自定义函数,启用批处理非常简单:
- 在自定义函数装饰器中设置
batching=True。 - 将参数和返回类型更改为
list。
例如,如果您想创建一个调用API为图像构建缩略图的自定义函数。
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip 有关更多详细信息,请参阅批处理文档。
:::
CocoIndex如何进行批处理
常见方法
批处理的工作原理是将传入请求收集到队列中,并决定将它们作为单个批次刷新的最佳时机。这个时机至关重要 — 如果处理得当,您可以同时平衡吞吐量、延迟和资源使用。
两种广泛使用的批处理策略主导了这一领域:
- 基于时间的批处理(每W毫秒刷新一次):在这种方法中,系统会刷新在固定W毫秒窗口内到达的所有请求。
-
优点:任何请求的最大等待时间是可预测的,实现也很简单。它确保即使在低流量期间,请求也不会无限期地留在队列中。
-
缺点:在稀疏流量期间,空闲请求会缓慢累积,增加早期到达请求的延迟。此外,最佳窗口W通常随工作负载特性而变化,需要仔细调整以在延迟和吞吐量之间取得适当平衡。
\
- 基于大小的批处理(当队列中有K个项目时刷新):在这里,一旦队列达到预定义的项目数K,就会触发批处理。
- 优点:批次大小是可预测的,这简化了内存管理和系统设计。很容易推断每个批次将消耗的资源。
- 缺点:当流量较轻时,请求可能会在队列中停留较长时间,增加最先到达项目的延迟。与基于时间的批处理一样,最佳K取决于工作负载模式,需要经验调整。
许多高性能系统采用混合方法:当时间窗口W到期或队列达到大小K时(以先发生者为准)刷新批次。这种策略捕获了两种方法的优点,在稀疏流量期间提高响应性,同时在高峰负载期间保持高效的批次大小。
尽管如此,批处理总是涉及可调参数和权衡。流量模式、工作负载特性和系统约束都会影响理想设置。实现最佳性能通常需要监控、分析和动态调整这些参数,以适应实时条件。
CocoIndex的方法
框架级别:自适应,无需调节
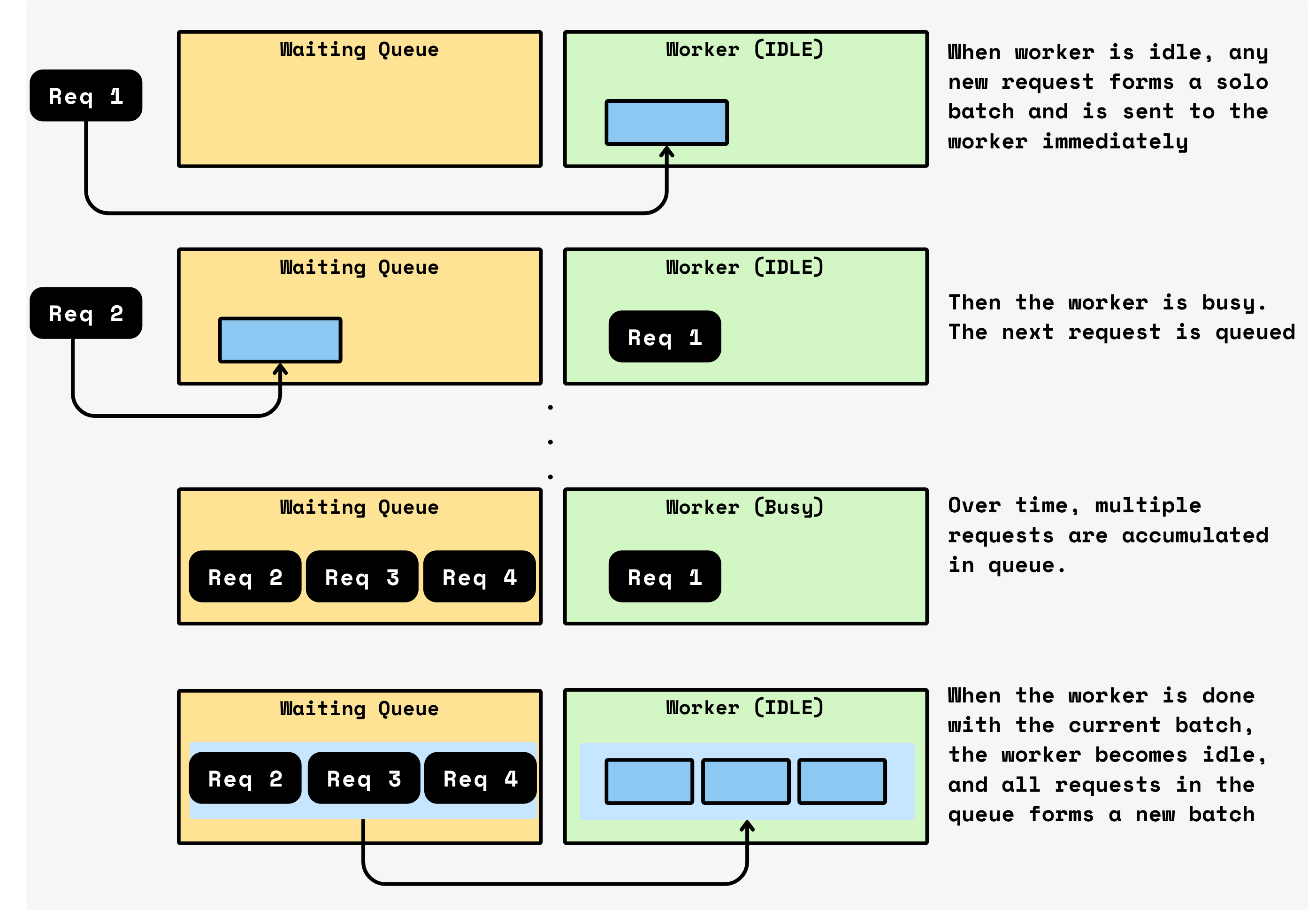
CocoIndex实现了一种简单自然的批处理机制,可自动适应传入的请求负载。该过程如下:
\
- 连续排队:当当前批次在设备(如GPU)上处理时,任何新传入的请求不会立即处理。相反,它们被排队。这允许系统在不中断正在进行的计算的情况下积累工作。
- 自动批处理窗口:当当前批次完成时,CocoIndex立即获取队列中积累的所有请求并将它们视为下一批次。这组请求形成新的批处理窗口。然后系统立即开始处理这个批次。
- 自适应批处理:没有计时器,没有固定批次大小,也没有预配置的阈值。每个批次的大小自然适应在前一批次服务时间内到达的流量。高流量期间自动产生更大的批次,最大化GPU利用率。低流量期间产生较小的批次,最小化早期请求的延迟。
本质上,CocoIndex的批处理机制是自调节的。它持续批量处理请求,同时允许批次大小反映实时需求,在不需要手动调整或复杂启发式方法的情况下实现高吞吐量。
\
\ 为什么这很好?
\
- 稀疏时低延
您可能也会喜欢
65+加密货币组织要求特朗普撤销对开发者Roman Storm的指控

SFO逮捕两名Basis Markets创始人涉及2800万美元加密货币丑闻
