

5个令人惊讶的当今人工智能无法真正"思考"的方式
大型语言模型(LLMs)的能力呈爆炸性增长,在从自然语言理解到代码生成的任务中展现出卓越的表现。我们每天都与它们互动,它们的流畅程度令人惊叹,将我们直接置于人工智能的恐怖谷中。但这种复杂的表现是否等同于真正的思考,还是仅仅是一种高科技幻象?
\ 越来越多的研究表明,在能力的帷幕背后隐藏着一系列深刻且违反直觉的局限性。本文探讨了五个最显著的失败案例,揭示了AI表现与真正的、类人理解之间的鸿沟。
它们不是更努力地推理;它们只是崩溃
苹果研究院最近发表的一篇题为"思考的幻觉"的论文揭示了即使是最先进的"大型推理模型"(LRMs)在使用思维链等技术时也存在关键缺陷。研究表明,这些模型并非真正在推理,而是复杂的模拟器,当问题变得足够复杂时就会遇到难以逾越的障碍。
\ 研究人员使用汉诺塔谜题来测试这些模型,根据谜题的复杂性确定了三种不同的性能状态:
\
- 低复杂度(3个圆盘):标准的非推理模型表现得与"思考型"LRM模型一样好,甚至更好。
- 中等复杂度(6个圆盘):生成更长思维链的LRM模型显示出明显优势。
- 高复杂度(7个或更多圆盘):两种模型类型都经历了"完全崩溃",准确率骤降至零。
\
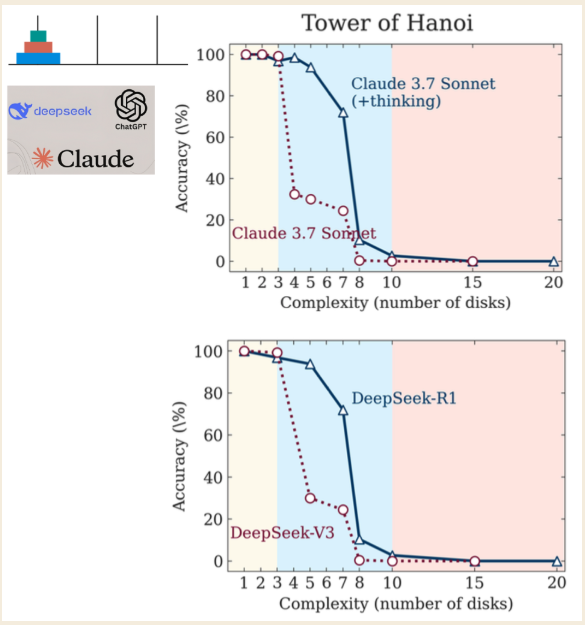
最违反直觉的发现是,随着问题变得更加困难,模型"思考"的程度反而降低。更糟糕的是,即使明确给出解决谜题所需的算法,它们也无法正确计算。这表明它们在压力下存在应用规则的根本性无能,是一种空洞的思维模仿,在最关键时刻崩溃。(研究人员指出,虽然竞争对手AI实验室Anthropic提出了异议,但这些只是小小的争论,而非对研究结果的根本反驳。)
\ 正如亚利桑那大学的研究人员所言,这种行为捕捉了幻觉的本质:
…表明LLM不是有原则的推理者,而是类似推理文本的复杂模拟器。
它们的"思维链"常常是海市蜃楼
思维链(CoT)是LLM在提供最终答案前写出其逐步"推理"的过程,这一功能旨在提高准确性并揭示其内部逻辑。然而,最近一项分析LLM如何处理基本算术的研究表明,这一过程常常是"脆弱的幻象"。
\ 令人吃惊的是,CoT中的推理步骤与模型提供的最终答案之间存在巨大不一致。在涉及简单加法的任务中,研究发现了一个令人震惊的现象:在超过60%的样本中,模型产生了不正确的推理步骤,但却以某种神秘的方式得出了正确的最终答案。
\ 这相当于一个学生在数学测试中展示了毫无意义的解题过程,却奇迹般地写下了正确的最终数字。你不会认为他们理解了材料;你会怀疑他们抄袭了答案。在AI中,这表明"推理"常常是事后的合理化,而非真正的思考过程。这不是通过扩大规模就能修复的错误;随着模型变得更加先进,问题反而变得更严重,这种矛盾行为的比率在GPT-4上增加到74%。
\ 如果模型的内部"思考过程"是海市蜃楼,当它被迫解决一个真实、复杂的问题时会发生什么?通常,它会陷入疯狂。
它们陷入"堕入疯狂"循环
当使用LLM进行复杂任务如调试代码时,可能会出现一种危险的模式:"堕入疯狂"或"幻觉循环"。这是一个反馈循环,LLM在尝试修复编程错误时,陷入一个无法终止的、非理性的循环。它提出看似合理的修复方案但失败了,当被要求提供另一个解决方案时,往往会重新引入原始错误,使用户陷入无果的循环。
\ 一项让程序员进行代码调试的研究揭示了AI辅助工作流程的惊人趋势。结果很明确:非AI辅助的程序员正确解决的任务更多,错误解决的任务更少,比使用LLM帮助的组表现更好。
\ 让这一点深入人心:在复杂的调试任务中,拥有最先进的AI助手不仅无益——它实际上是有害的,导致的结果比完全没有AI还要糟糕。使用AI的参与者经常陷入这些无果的循环,浪费时间在概念上毫无根据的修复上。研究人员还发现了"嘈杂解决方案"问题,即正确的修复被埋没在一堆无关建议中,这是人类挫折感的完美配方。这种有缺陷的"辅助"突显了AI令人印象深刻的外表如何掩盖其深度不可靠的核心,尤其是在风险较高时。
它们令人印象深刻的基准建立在缺陷基础上
当AI公司发布新模型时,他们指向令人印象深刻的基准分数来证明其优越性。然而,仔细观察可能会揭示出一幅不那么令人满意的图景。
\ SWE-bench(软件工程基准)用于衡量LLM修复GitHub上真实世界软件问题的能力,是一个典型案例研究。约克大学的一项独立研究发现了严重缺陷,这些缺陷极大地夸大了模型的感知能力:
\
- 解决方案泄露("作弊"):在32.67%的成功补丁中,正确的解决方案已经在问题报告本身中提供。
- 弱测试:在模型"通过"的31.08%的案例中,验证测试太弱,无法真正确认修复是否正确。
\ 当这些有缺陷的实例被过滤掉后,顶级模型(SWE-Agent + GPT-4)的真实世界性能直线下降。其解决率从宣传的12.47%降至仅3.97%。此外,基准中超过94%的问题是在LLM知识截止日期之前创建的,这引发了关于数据泄露的严重质疑。
\ 这揭示了一个令人不安的现实:基准测试通常是营销工具,呈现出最佳情况、实验室培育的场景,在真实世界的审视下崩溃。宣传的能力与经验证的性能之间的差距不是裂缝;而是峡谷。
它们掌握规则但根本缺乏理解
即使上述所有技术故障都被修复,一个更深层次、更哲学的障碍仍然存在。LLM缺乏人类智能的核心组成部分。虽然哲学家讨论意识和意向性,但许多论点表明,理性,即我们把握普遍概念和逻辑推理的能力,是人类独有而AI所缺乏的关键方面。
\ 这一观点得到了物理学家罗杰·彭罗斯的强化,他使用哥德尔不完备定理来论证人类数学理解超越了任何固定的算法规则集。将任何算法视为有限的规则书。哥德尔定理表明,人类数学家总能从外部看待规则书,理解规则书本身无法证明的真理。
\ 我们的思维不仅仅是遵循书中的规则;我们可以阅读整本书并把握其局限性。这种洞察力,这种"不可计算"的理解,是将人类认知与最先进的AI区分开来的因素。
\ LLM是基于算法和统计模式操纵符号的大师。然而,它们不具备真正理解所需的意识。正如一个有力的论点所总结的:
魔术师的把戏
虽然LLM无疑是强大的工具,能以惊人的准确度模拟智能行为,但越来越多的证据表明它们更像是复杂的模拟器,而非真正的思考者。它们的表现是一种宏大的幻觉,一场在压力下崩溃、自相矛盾并依赖有缺陷指标的能力炫目表演。这类似于魔术师的把戏(看似不可能),但最终是建立在巧妙技巧而非真正魔法上的幻觉。随着我们继续将这些系统整合到我们的世界中,我们必须保持批判性并提出本质问题:
\ 如果这些AI机器在更难的问题上崩溃,即使你给它们算法和规则,它们是真的在思考还是只是伪装得很好?
播客:
\
- Apple: 此处
- Spotify: 此处
\
您可能也会喜欢

DTCC 将 Bitwise 的现货 Chainlink ETF 列在股票代码 CLNK 下

Polymarket 和 PrizePicks 联合推动 2025 年预测市场爆炸性增长
