

数据稀缺解决方案:用于CT到超声波转换的S-CycleGAN
链接表
摘要和1 引言
-
相关工作
-
问题设置
-
方法论
4.1. 决策边界感知蒸馏
4.2. 知识巩固
-
实验结果和5.1. 实验设置
5.2. 与最先进方法的比较
5.3. 消融研究
-
结论和未来工作及参考文献
\
补充材料
- IIL中KCEMA机制理论分析的详细信息
- 算法概述
- 数据集详情
- 实现细节
- 灰尘输入图像的可视化
- 更多实验结果
摘要
实例增量学习(IIL)专注于使用相同类别的数据持续学习。与类增量学习(CIL)相比,IIL较少被探索,因为IIL受灾难性遗忘(CF)的影响较小。然而,除了保留知识外,在类空间总是预定义的实际部署场景中,在可能无法获取先前数据的情况下进行持续且经济高效的模型提升是更为重要的需求。因此,我们首先将新的更实用的IIL设置定义为仅通过新观察来提升模型性能并抵抗CF。在新的IIL设置中必须解决两个问题:1)由于无法访问旧数据导致的灾难性遗忘问题,以及2)由于概念漂移而需要扩展现有决策边界以适应新观察。为解决这些问题,我们的关键见解是适度扩展决策边界以应对失败案例,同时保留旧边界。因此,我们提出了一种新颖的决策边界感知蒸馏方法,通过将知识巩固到教师模型来简化学生学习新知识的过程。我们还在现有数据集Cifar-100和ImageNet上建立了基准。值得注意的是,大量实验表明,教师模型可以成为比学生模型更好的增量学习者,这颠覆了之前将学生视为主角的基于知识蒸馏的方法。
1. 引言
近年来,许多优秀的基于深度学习的网络被提出用于各种任务,如图像分类、分割和检测。尽管这些网络在训练数据上表现良好,但在实际应用中它们不可避免地会在一些未经训练的新数据上失败。持续有效地提升已部署模型在这些新数据上的性能是一个重要需求。当前使用所有累积数据重新训练网络的解决方案有两个缺点:1)随着数据规模增加,每次训练成本变得更高,例如,更多的GPU小时和更大的碳足迹[20],以及2)在某些情况下,由于隐私政策或数据存储预算有限,旧数据不再可访问。在只有少量或没有旧数据可用或利用的情况下,用新数据重新训练深度学习模型总是会导致在旧数据上性能下降,即灾难性遗忘(CF)问题。为解决CF问题,提出了增量学习[4, 5, 22, 29],也称为持续学习。增量学习显著提升了深度学习模型的实用价值,并吸引了强烈的研究兴趣。
\ 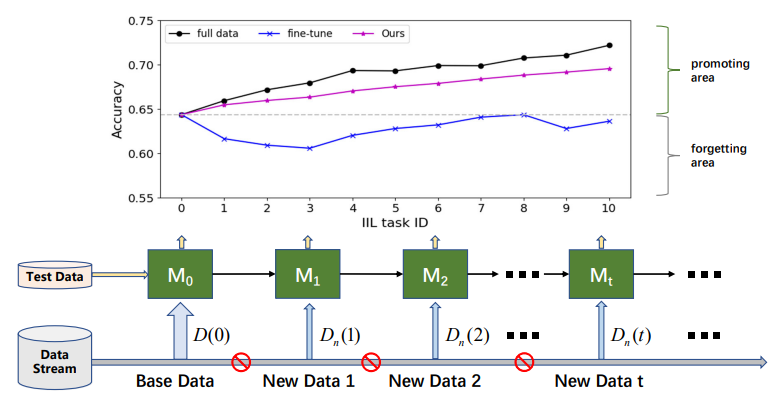
\ 根据新数据是否来自已见类别,增量学习可分为三种场景[16, 17]:实例增量学习(IIL)[3, 16],其中所有新数据属于已见类别;类增量学习(CIL)[4, 12, 15, 22],其中新数据具有不同的类别标签;以及混合增量学习[6, 30],其中新数据由来自旧类和新类的新观察组成。与CIL相比,IIL相对未被充分探索,因为它受CF影响较小。Lomonaco和Maltoni[16]报告说,使用早停的微调可以很好地控制IIL中的CF问题。然而,当无法访问旧训练数据且新数据比旧数据小得多时,这一结论并不总是成立,如图1所示。微调通常导致决策边界的移动,而不是扩展它以适应新观察。除了保留旧知识外,实际部署更关注IIL中的高效模型提升。例如,在工业产品的缺陷检测中,缺陷类别总是限于已知类别。但这些缺陷的形态随时间变化。应及时有效地纠正那些未见缺陷上的失败,以避免有缺陷的产品流入市场。不幸的是,现有研究主要关注保留旧数据上的知识,而不是用新观察丰富知识。
\ 在本文中,为了快速且经济高效地使用已见类别的新观察来增强训练模型,我们首先将新的IIL设置定义为在没有访问旧数据的情况下,保留已学习的知识并提升模型在新观察上的性能。简言之,我们旨在仅利用新数据提升现有模型,并获得与使用所有累积数据重新训练的模型相当的性能。由于新观察引起的概念漂移[6],如与旧数据相比的颜色或形状变化,新的IIL具有挑战性。因此,在新的IIL设置中必须解决两个问题:1)由于无法访问旧数据导致的灾难性遗忘,以及2)扩展现有决策边界以适应新观察。
\ 为解决新IIL设置中的上述问题,我们提出了一个基于教师-学生结构的新型IIL框架。所提出的框架包括决策边界感知蒸馏(DBD)过程和知识巩固(KC)过程。DBD允许学生模型从新观察中学习,同时意识到现有的类间决策边界,这使模型能够确定在哪里加强知识以及在哪里保留知识。然而,当由于在IIL中无法访问旧数据而导致边界周围的样本不足时,决策边界是无法追踪的。为克服这一点,我们从用面粉撒在地板上显示隐藏足迹的做法中获得灵感。类似地,我们引入随机高斯噪声来污染输入空间,并显现已学习的决策边界用于蒸馏。在使用边界蒸馏训练学生模型的过程中,更新的知识通过EMA机制[28]间歇性地反复巩固回教师模型。将教师模型用作目标模型是一种开创性尝试,其可行性在理论上得到解释。
\ 根据新的IIL设置,我们重新组织了CIL中常用的一些现有数据集的训练集,如Cifar-100[11]和ImageNet[24],以建立基准。在每个增量阶段,模型在测试数据以及不可用的基础数据上进行评估。我们的主要贡献可总结如下:1)我们定义了一个新的IIL设置,寻求对新观察进行快速且经济高效的模型提升,并建立了基准;2)我们提出了一种新颖的决策边界感知蒸馏方法,既保留已学习的知识,又用新数据丰富它;3)我们创造性地将学生模型学到的知识巩固到教师模型,以获得更好的性能和泛化能力,并从理论上证明了其可行性;以及4)大量实验表明,所提出的方法能很好地仅使用新数据积累知识,而大多数现有增量学习方法则失败了。
\
:::info 本论文可在arxiv上获取,遵循CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International)许可。
:::
:::info 作者:
(1) 聂强,香港科技大学(广州);
(2) 付伟福,腾讯优图实验室;
(3) 林宇欢,腾讯优图实验室;
(4) 李佳林,腾讯优图实验室;
(5) 周一峰,腾讯优图实验室;
(6) 刘勇,腾讯优图实验室;
(7) 聂强,香港科技大学(广州);
(8) 王成杰,腾讯优图实验室。
:::
\
您可能也会喜欢

比特币专家直言不讳:Saylor和Kiyosaki发表年度预测

Hedera 获得其首个 ETF:Canary 的 HBAR 基金让投资者进军代币化热潮
