

本节定义了一个新的、实用的实例增量学习(IIL)问题设置,专注于已部署系统中的成本效益模型提升。本节定义了一个新的、实用的实例增量学习(IIL)问题设置,专注于已部署系统中的成本效益模型提升。
新的 IIL 设置:仅使用新数据增强已部署的模型
2025/11/05 23:00
链接表
摘要和1 引言
-
相关工作
-
问题设定
-
方法论
4.1. 决策边界感知蒸馏
4.2. 知识巩固
-
实验结果和5.1. 实验设置
5.2. 与最先进方法的比较
5.3. 消融研究
-
结论和未来工作及参考文献
\
补充材料
- IIL中KCEMA机制理论分析的详细信息
- 算法概述
- 数据集详情
- 实现细节
- 灰尘输入图像的可视化
- 更多实验结果
3. 问题设定
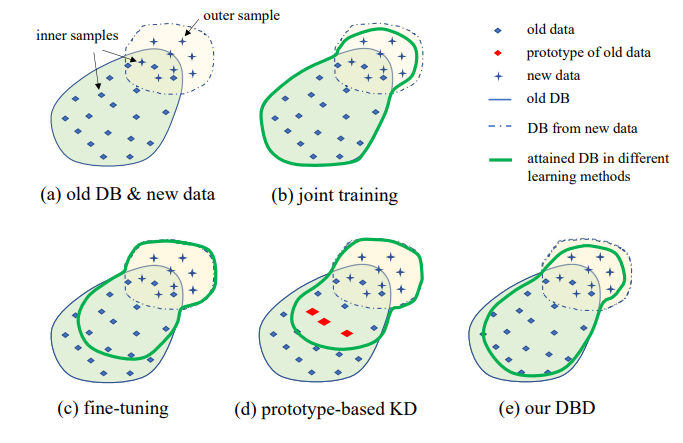
所提出的IIL设置的说明如图1所示。如图所示,数据在数据流中持续不可预测地生成。通常在实际应用中,人们倾向于首先收集足够的数据并训练一个强大的模型M0用于部署。无论模型多么强大,它不可避免地会遇到分布外数据并在其上失败。这些失败案例和其他低分新观察将被标注以不时训练模型。每次用所有累积数据重新训练模型会导致时间和资源成本越来越高。因此,新的IIL旨在每次仅使用新数据来增强现有模型。
\ 
\ 
\
:::info 作者:
(1) 聂强,香港科技大学(广州);
(2) 付伟福,腾讯优图实验室;
(3) 林宇欢,腾讯优图实验室;
(4) 李佳林,腾讯优图实验室;
(5) 周一峰,腾讯优图实验室;
(6) 刘勇,腾讯优图实验室;
(7) 聂强,香港科技大学(广州);
(8) 王成杰,腾讯优图实验室。
:::
:::info 本论文可在arxiv上获取,遵循CC BY-NC-ND 4.0 Deed(署名-非商业性使用-禁止演绎4.0国际)许可。
:::
\
免责声明: 本网站转载的文章均来源于公开平台,仅供参考。这些文章不代表 MEXC 的观点或意见。所有版权归原作者所有。如果您认为任何转载文章侵犯了第三方权利,请联系 service@support.mexc.com 以便将其删除。MEXC 不对转载文章的及时性、准确性或完整性作出任何陈述或保证,并且不对基于此类内容所采取的任何行动或决定承担责任。转载材料仅供参考,不构成任何商业、金融、法律和/或税务决策的建议、认可或依据。
分享文章
您可能也会喜欢

Reddit、Kick被添加到澳大利亚不断增长的青少年社交媒体黑名单中
TLDRs; 澳大利亚将其16岁以下社交媒体禁令扩大至包括Reddit和Kick,从12月10日开始实施。不合规公司将面临高达4950万澳元(3200万美元)的罚款。平台必须使用生物识别、身份证明或基于上下文的工具验证用户年龄,尽管这些方法存在高错误率。隐私规则限制数据收集,使2025年执法前的合规变得更加复杂。澳大利亚已[...]这篇文章《Reddit和Kick被添加到澳大利亚不断扩大的青少年社交媒体黑名单中》首次发表于CoinCentral。
分享
Coincentral2025/11/06 04:44

这些山寨币在市场下跌时获利:这里是产生最多收入的项目
在过去一个月内,哪些山寨币在加密货币市场上产生了最多的平台收入?以下是详细信息。继续阅读:这些山寨币在市场下跌时仍在获利:以下是产生最多收入的项目
分享
Coinstats2025/11/06 04:01

特朗普关税之战在最高法院前出现意外转折
随着最高法院评估特朗普引入的关税,一个重要的日子展开,这对全球贸易和加密货币市场都带来了关键影响。这些关税的推翻,可能会逆转过去几个月取得的进展,是此次司法审查的核心。继续阅读:特朗普关税战在最高法院前的意外转折
分享
Coinstats2025/11/06 04:10