

解决 3D 分割的最大瓶颈
:::info 作者:
(1) George Tang,麻省理工学院;
(2) Krishna Murthy Jatavallabhula,麻省理工学院;
(3) Antonio Torralba,麻省理工学院。
:::
链接目录
摘要和第一章 引言
第二章 背景
第三章 方法
第四章 实验
第五章 结论和参考文献
\ 
\ 摘要—我们解决了从一系列已知姿态的RGB图像中学习3D实例分割的隐式场景表示问题。为此,我们引入了3DIML,一个新颖的框架,它有效地学习一个标签场,可以从新视角渲染出视图一致的实例分割掩码。3DIML显著改进了现有基于隐式场景表示方法的训练和推理运行时间。与之前以自监督方式优化神经场的方法不同,后者需要复杂的训练程序和损失函数设计,3DIML利用两阶段过程。第一阶段InstanceMap,输入由前端实例分割模型生成的图像序列的2D分割掩码,并将跨图像的对应掩码关联到3D标签。这些几乎视图一致的伪标签掩码随后在第二阶段InstanceLift中用于监督神经标签场的训练,该标签场插值InstanceMap遗漏的区域并解决歧义。此外,我们引入了InstanceLoc,它通过融合两者的输出,实现了给定训练好的标签场和现成图像分割模型的实例掩码的近实时定位。我们在Replica和ScanNet数据集的序列上评估了3DIML,并在图像序列的温和假设下展示了3DIML的有效性。我们在保持可比质量的同时,相比现有隐式场景表示方法实现了巨大的实际加速,展示了其促进更快速、更有效3D场景理解的潜力。
I. 引言
智能代理需要在对象级别上理解场景,以有效执行特定上下文的操作,如导航和操作。虽然从图像中分割对象已经通过在互联网规模数据集上训练的可扩展模型取得了显著进展[1],[2],但将这些能力扩展到3D环境仍然具有挑战性。
\ 在本工作中,我们解决了从已知姿态的2D图像中学习3D场景表示的问题,该表示将底层场景分解为其组成对象的集合。解决这个问题的现有方法集中在训练类别无关的3D分割模型[3],[4],需要大量标注的3D数据,并直接在显式3D场景表示(如点云)上操作。另一类方法[5],[6]则提出直接将现成实例分割模型的分割掩码提升到隐式3D表示中,如神经辐射场(NeRF)[7],使其能够从新视角渲染3D一致的实例掩码。
\ 然而,基于神经场的方法一直难以优化,[5]和[6]需要几个小时来优化低到中等分辨率的图像(如300×640)。特别是,全景提升[5]随场景中对象数量的增加呈立方增长,阻止其应用于包含数百个对象的场景,而对比提升[6]需要复杂的多阶段训练程序,阻碍了其在机器人应用中的实用性。
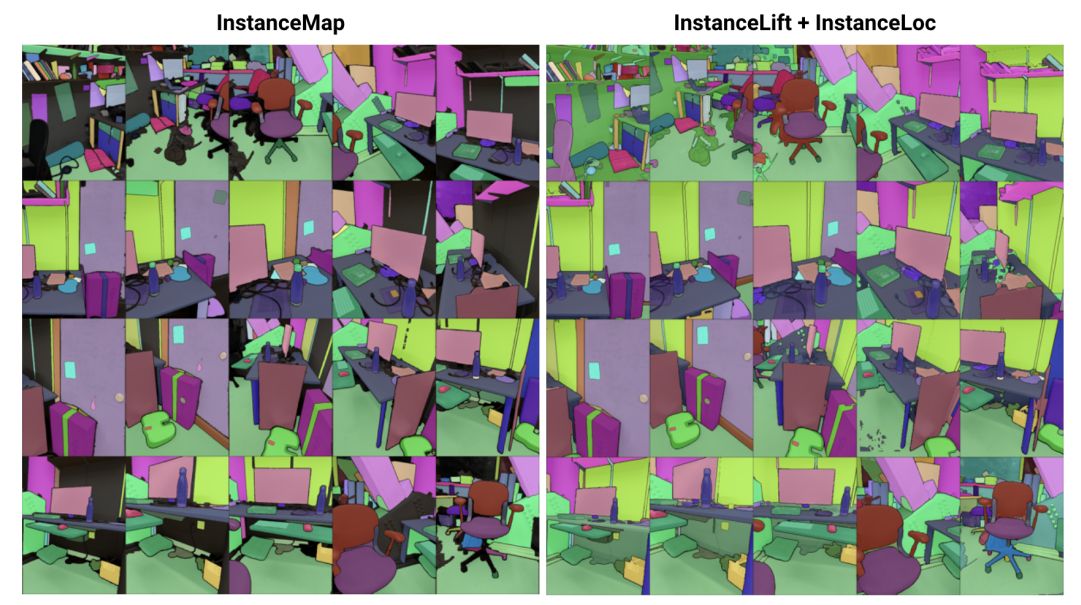
\ 为此,我们提出3DIML,一种从已知姿态RGB图像中学习3D一致实例分割的高效技术。3DIML包括两个阶段:InstanceMap和InstanceLift。给定使用前端实例分割模型[2]从RGB序列中提取的视图不一致2D实例掩码,InstanceMap生成一系列视图一致的实例掩码。为此,我们首先使用相似图像对之间的关键点匹配来关联跨帧的掩码。然后我们使用这些可能有噪声的关联来监督神经标签场InstanceLift,它利用3D结构来插值缺失的标签并解决歧义。与需要多阶段训练和额外损失函数工程的先前工作不同,我们使用单一渲染损失进行实例标签监督,使训练过程能够显著更快地收敛。3DIML的总运行时间,包括InstanceMap,需要10-20分钟,而先前的方法需要3-6小时。
\ 此外,我们设计了InstaLoc,一个快速定位管道,它接收新视图并定位该图像中分割的所有实例(使用快速实例分割模型[8]),通过稀疏查询标签场并融合标签预测与提取的图像区域。最后,3DIML极其模块化,我们可以轻松替换我们方法的组件,以便在更高性能的组件可用时使用它们。
\ 总结我们的贡献:
\ • 一种高效的神经场学习方法,将3D场景分解为其组成对象
\ • 一种快速实例定位算法,融合对训练好的标签场的稀疏查询与高性能图像实例分割模型,生成3D一致的实例分割掩码
\ • 在单个GPU(NVIDIA RTX 3090)上基准测试,相比先前技术整体实际运行时间提升了14-24倍
II. 背景
2D分割:视觉transformer架构的普及和图像数据集规模的增加导致了一系列最先进的图像分割模型。全景提升和对比提升都通过学习神经场将Mask2Former[1]生成的全景分割掩码提升到3D。在开放集分割方面,segment anything(SAM)[2]通过在1100万张图像上训练10亿个掩码,实现了前所未有的性能。HQ-SAM[9]改进了SAM以获得细粒度掩码。FastSAM[8]将SAM提炼为CNN架构,实现了类似性能但速度提高了数个数量级。在本工作中,我们使用GroundedSAM[10],[11],它改进了SAM以生成对象级而非部件级分割掩码。
\ 用于3D实例分割的神经场:NeRF是隐式场景表示,可以准确编码复杂几何、语义和其他模态,以及解决视点不一致的监督[12]。全景提升[5]在NeRF的高效变体TensoRF[13]上构建语义和实例分支,利用匈牙利匹配损失函数将学习的实例掩码分配给给定参考视图不一致掩码的代理对象ID。这随着对象数量的增加而扩展性能差(由于匈牙利匹配的立方复杂度)。对比提升[6]通过在场景特征上采用对比学习来解决这个问题,正负关系由它们是否投影到同一掩码上决定。此外,对比提升需要一个慢-快聚类基础损失以实现稳定训练,导致比全景提升更快的性能,但需要多阶段训练,导致收敛缓慢。与我们同时,Instance-NeRF[14]直接学习标签场,但他们的掩码关联基于利用NeRF-RPN[15]在NeRF中检测对象。相反,我们的方法允许扩展到非常高的图像分辨率,同时仅需少量(40-60)神经场查询来渲染分割掩码。
\ 运动结构恢复:在InstanceMap中的掩码关联过程中,我们从可扩展3D重建管道如hLoc[16]中获取灵感,包括首先使用视觉描述符匹配图像视点,然后应用关键点匹配作为掩码关联的初步步骤。我们使用LoFTR[17]进行关键点提取和匹配。
\
:::info 本论文可在arxiv上获取,遵循CC by 4.0 Deed(Attribution 4.0 International)许可。
:::
\
您可能也会喜欢

谷歌量子突破使比特币威胁"更加真实",科学家表示

美国股市对CPI通胀报告作出反应 – 道指跳涨350点
