基于变换器的使用日志序列嵌入的异常检测
链接表
摘要
1 引言
2 背景和相关工作
2.1 基于日志的异常检测任务的不同表述
2.2 监督式与非监督式
2.3 日志数据中的信息
2.4 固定窗口分组
2.5 相关工作
3 一种可配置的基于Transformer的异常检测方法
3.1 问题表述
3.2 日志解析和日志嵌入
3.3 位置和时间编码
3.4 模型结构
3.5 监督式二元分类
4 实验设置
4.1 数据集
4.2 评估指标
4.3 生成不同长度的日志序列
4.4 实现细节和实验环境
5 实验结果
5.1 研究问题1:与基准相比,我们提出的异常检测模型表现如何?
5.2 研究问题2:日志序列中的顺序和时间信息对异常检测有多大影响?
5.3 研究问题3:不同类型的信息各自对异常检测贡献多少?
6 讨论
7 有效性威胁
8 结论和参考文献
\
3 一种可配置的基于Transformer的异常检测方法
在本研究中,我们介绍了一种新颖的基于transformer的异常检测方法。该模型以日志序列作为输入来检测异常。模型采用预训练的BERT模型嵌入日志模板,使日志消息中的语义信息得以表示。这些嵌入与位置或时间编码相结合,随后输入到transformer模型中。这些组合信息在后续生成日志序列级表示中被利用,促进了异常检测过程。我们设计的模型具有灵活性:输入特征是可配置的,因此我们可以使用或进行不同日志数据特征组合的实验。此外,该模型设计并训练为能处理不同长度的输入日志序列。在本节中,我们介绍我们的问题表述和方法的详细设计。
\ 3.1 问题表述
我们遵循先前的工作[1],将任务表述为二元分类任务,在该任务中,我们以监督方式训练我们提出的模型,将日志序列分类为异常和正常。对于用于模型训练和评估的样本,我们采用灵活的分组方法生成不同长度的日志序列。详细内容在第4节介绍
\ 3.2 日志解析和日志嵌入
在我们的工作中,我们通过使用预训练语言模型编码日志模板,将日志事件转换为数值向量。为了获取日志模板,我们采用Drain解析器[24],它被广泛使用并在大多数公共数据集上具有良好的解析性能[4]。我们使用预训练的sentence-bert模型[25](即all-MiniLML6-v2[26])嵌入由日志解析过程生成的日志模板。该预训练模型通过对比学习目标进行训练,并在各种NLP任务上达到了最先进的性能。我们利用这个预训练模型创建一个表示,捕获日志消息的语义信息,并为下游异常检测模型说明日志模板之间的相似性。模型的输出维度为384。
\ 3.3 位置和时间编码
原始transformer模型[27]采用位置编码,使模型能够利用输入序列的顺序。由于模型不包含循环和卷积,如果没有位置编码,模型将无法识别日志序列。虽然一些研究表明,在处理顺序数据时,没有显式位置编码的transformer模型仍然与标准模型具有竞争力[28, 29],但重要的是要注意,输入序列的任何排列都将产生相同的模型内部状态。由于顺序信息或时间信息可能是日志序列中异常的重要指标,基于transformer模型的先前工作利用标准位置编码注入序列中日志事件或模板的顺序[11, 12, 21],旨在检测与错误执行顺序相关的异常。然而,我们注意到,在一个常用的基于transformer方法的复制实现中[5],实际上省略了位置编码。据我们所知,尚无现有工作基于日志时间戳对其异常检测方法进行时间信息编码。在异常检测任务中利用顺序或时间信息的有效性尚不清楚。
\ 在我们提出的方法中,我们尝试将顺序和时间编码纳入transformer模型,并探索顺序和时间信息对异常检测的重要性。具体而言,我们提出的方法有不同变体,利用以下顺序或时间编码技术。编码随后添加到日志表示中,作为transformer结构的输入。
\ 
3.3.1 相对时间流逝编码(RTEE)
我们提出这种时间编码方法RTEE,它简单地用每个日志事件的时间替代位置编码中的位置索引。我们首先根据日志序列中日志事件的时间戳计算时间流逝。我们不使用日志事件序列索引作为正弦和余弦方程的位置,而是使用相对于日志序列中第一个日志事件的相对时间流逝来替代位置索引。表1显示了日志序列中时间间隔的示例。在示例中,我们有一个包含7个事件、时间跨度为7秒的日志序列。从第一个事件到序列中每个事件的经过时间用于计算相应事件的时间编码。与位置编码类似,编码使用上述方程1计算,并且在训练过程中不会更新。
\ 
3.4 模型结构
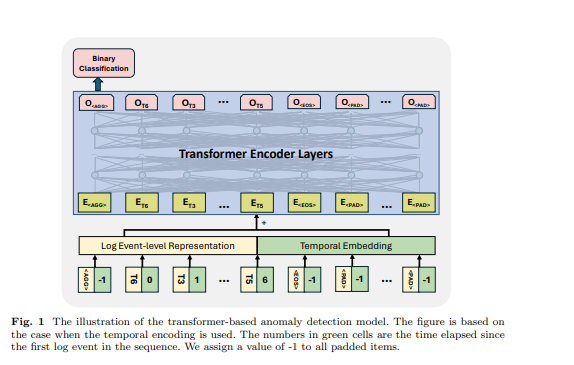
Transformer是一种依赖自注意力机制捕获序列中输入元素之间关系的神经网络架构。基于transformer的模型和框架已被许多先前工作用于异常检测任务[6, 11, 12, 21]。受先前工作的启发,我们使用基于transformer编码器的模型进行异常检测。我们设计的方法接受不同长度的日志序列并生成序列级表示。为实现这一点,我们在输入日志序列中使用了一些特定标记,使模型能够生成序列表示并识别填充标记和日志序列的结束,这一灵感来自BERT模型[31]的设计。在输入日志序列中,我们使用以下标记:放置在每个序列开始处,使模型能够为整个序列生成聚合信息;添加在序列末尾,表示其完成;用于标记自监督训练范式下的掩码标记;用于填充标记。这些特殊标记的嵌入是基于所使用的日志表示维度随机生成的。图1中显示了一个示例,、和的时间流逝设置为-1。日志事件级表示和位置或时间嵌入相加作为transformer结构的输入特征。
\ 3.5 监督式二元分类 在这个训练目标下,我们利用transformer模型第一个标记的输出,同时忽略其他标记的输出。第一个标记的这个输出旨在聚合整个输入日志序列的信息,类似于BERT模型的标记,它提供了标记序列的聚合表示。因此,我们将此标记的输出视为序列级表示。我们使用二元分类目标(即二元交叉熵损失)和这个表示训练模型。
\ 
:::info 作者:
- 吴兴方
- 李恒
- Foutse Khomh
:::
:::info 本论文可在arxiv上获取,遵循CC by 4.0 Deed(署名4.0国际)许可。
:::
\
您可能也会喜欢

比特币挖矿热潮将伊朗变成"非法矿工的天堂" – CEO

Ripple 倡导者 Bill Morgan 强调 Reliance 的 1700 万美元 XRP 投资