

資料稀缺解決方案:S-CycleGAN 用於 CT 到超音波的轉換
連結表格
摘要和1 引言
-
相關工作
-
問題設定
-
方法論
4.1. 決策邊界感知蒸餾
4.2. 知識鞏固
-
實驗結果和5.1. 實驗設置
5.2. 與最先進方法的比較
5.3. 消融研究
-
結論和未來工作及參考文獻
\
補充材料
- IIL中KCEMA機制理論分析的詳細信息
- 算法概述
- 數據集詳情
- 實現細節
- 灑塵輸入圖像的可視化
- 更多實驗結果
摘要
實例增量學習(IIL)專注於使用相同類別的數據持續學習。與類別增量學習(CIL)相比,IIL較少被探索,因為IIL受災難性遺忘(CF)的影響較小。然而,除了保留知識外,在類別空間總是預定義的實際部署場景中,在可能無法獲取先前數據的情況下進行持續且具成本效益的模型提升是更為重要的需求。因此,我們首先將新的且更實用的IIL設定定義為僅通過新觀察來提升模型性能並抵抗CF。在新的IIL設定中必須解決兩個問題:1)由於無法訪問舊數據而導致的災難性遺忘問題,以及2)由於概念漂移而需要擴展現有決策邊界以適應新觀察。為解決這些問題,我們的關鍵見解是適度擴展決策邊界以應對失敗案例,同時保留舊邊界。因此,我們提出了一種新穎的決策邊界感知蒸餾方法,通過將知識鞏固到教師模型來幫助學生學習新知識。我們還在現有的Cifar-100和ImageNet數據集上建立了基準。值得注意的是,大量實驗表明,教師模型可以成為比學生模型更好的增量學習者,這顛覆了之前將學生視為主角的知識蒸餾方法。
1. 引言
近年來,許多優秀的基於深度學習的網絡被提出用於各種任務,如圖像分類、分割和檢測。雖然這些網絡在訓練數據上表現良好,但在實際應用中,它們不可避免地會在一些未經訓練的新數據上失敗。持續有效地提升已部署模型在這些新數據上的性能是一個重要需求。目前使用所有累積數據重新訓練網絡的解決方案有兩個缺點:1)隨著數據規模增加,每次訓練成本變得更高,例如,更多的GPU小時和更大的碳足跡[20],以及2)在某些情況下,由於隱私政策或數據存儲預算有限,舊數據不再可訪問。在只有少量或沒有舊數據可用或利用的情況下,用新數據重新訓練深度學習模型總是會導致在舊數據上的性能下降,即災難性遺忘(CF)問題。為解決CF問題,增量學習[4, 5, 22, 29],也稱為持續學習,被提出。增量學習顯著提升了深度學習模型的實用價值,並吸引了強烈的研究興趣。
\ 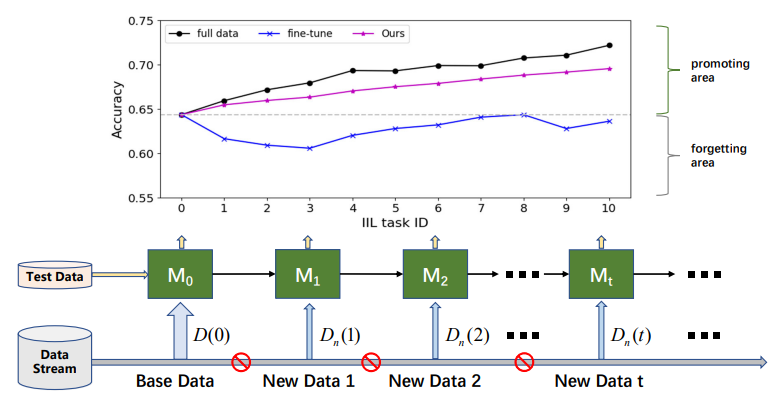
\ 根據新數據是否來自已見類別,增量學習可分為三種情境[16, 17]:實例增量學習(IIL)[3, 16],其中所有新數據屬於已見類別;類別增量學習(CIL)[4, 12, 15, 22],其中新數據具有不同的類別標籤;以及混合增量學習[6, 30],其中新數據由來自舊類別和新類別的新觀察組成。與CIL相比,IIL相對較少被探索,因為它較不容易受到CF的影響。Lomonaco和Maltoni[16]報告說,使用早停的微調可以很好地控制IIL中的CF問題。然而,當無法訪問舊訓練數據且新數據比舊數據小得多時,這一結論並不總是成立,如圖1所示。微調通常導致決策邊界的移動,而不是擴展它以適應新觀察。除了保留舊知識外,實際部署更關注IIL中的高效模型提升。例如,在工業產品的缺陷檢測中,缺陷類別總是限於已知類別。但這些缺陷的形態會隨時間變化。應及時有效地糾正那些未見缺陷上的失敗,以避免有缺陷的產品流入市場。不幸的是,現有研究主要關注保留舊數據上的知識,而不是用新觀察豐富知識。
\ 在本文中,為了快速且具成本效益地使用已見類別的新觀察來增強已訓練的模型,我們首先將新的IIL設定定義為保留已學知識並在沒有訪問舊數據的情況下提升模型在新觀察上的性能。簡而言之,我們的目標是僅通過利用新數據來提升現有模型,並達到與使用所有累積數據重新訓練的模型相當的性能。新的IIL具有挑戰性,因為新觀察引起的概念漂移[6],例如與舊數據相比的顏色或形狀變化。因此,在新的IIL設定中必須解決兩個問題:1)由於無法訪問舊數據而導致的災難性遺忘,以及2)擴展現有決策邊界以適應新觀察。
\ 為解決新IIL設定中的上述問題,我們提出了一個基於教師-學生結構的新穎IIL框架。所提出的框架包括決策邊界感知蒸餾(DBD)過程和知識鞏固(KC)過程。DBD允許學生模型從新觀察中學習,同時意識到現有的類間決策邊界,這使模型能夠確定在哪裡加強其知識以及在哪裡保留它。然而,當由於在IIL中無法訪問舊數據而導致邊界周圍的樣本不足時,決策邊界是無法追蹤的。為克服這一點,我們從用麵粉灑在地板上顯示隱藏足跡的做法中獲得靈感。類似地,我們引入隨機高斯噪聲來污染輸入空間並顯現已學習的決策邊界用於蒸餾。在使用邊界蒸餾訓練學生模型的過程中,更新的知識通過EMA機制[28]間歇性地反覆鞏固回教師模型。將教師模型用作目標模型是一種開創性嘗試,其可行性在理論上得到解釋。
\ 根據新的IIL設定,我們重新組織了CIL中常用的一些現有數據集的訓練集,如Cifar-100[11]和ImageNet[24],以建立基準。在每個增量階段,模型在測試數據以及不可用的基礎數據上進行評估。我們的主要貢獻可總結如下:1)我們定義了一個新的IIL設定,尋求對新觀察進行快速且具成本效益的模型提升,並建立了基準;2)我們提出了一種新穎的決策邊界感知蒸餾方法,以保留已學知識並用新數據豐富它;3)我們創新地將學生模型學到的知識鞏固到教師模型,以獲得更好的性能和泛化能力,並在理論上證明了其可行性;以及4)大量實驗表明,所提出的方法能很好地僅用新數據累積知識,而大多數現有增量學習方法則失敗了。
\
:::info 本論文可在arxiv上獲取,遵循CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International)許可證。
:::
:::info 作者:
(1) 聶強,香港科技大學(廣州);
(2) 傅偉富,騰訊優圖實驗室;
(3) 林宇歡,騰訊優圖實驗室;
(4) 李嘉林,騰訊優圖實驗室;
(5) 周一峰,騰訊優圖實驗室;
(6) 劉勇,騰訊優圖實驗室;
(7) 聶強,香港科技大學(廣州);
(8) 王成傑,騰訊優圖實驗室。
:::
\
您可能也會喜歡

Bitcoin 專家直言不諱:Saylor 和 Kiyosaki 發表年度預測

Hedera 獲得其首個 ETF:Canary 的 HBAR 基金讓投資者參與代幣化熱潮
