

基於 Transformer 的日誌序列嵌入異常檢測
連結表格
摘要
1 引言
2 背景與相關工作
2.1 基於日誌的異常檢測任務的不同公式
2.2 監督式 vs. 非監督式
2.3 日誌數據中的信息
2.4 固定窗口分組
2.5 相關工作
3 可配置的基於 Transformer 的異常檢測方法
3.1 問題公式化
3.2 日誌解析與日誌嵌入
3.3 位置與時間編碼
3.4 模型結構
3.5 監督式二元分類
4 實驗設置
4.1 數據集
4.2 評估指標
4.3 生成不同長度的日誌序列
4.4 實現細節與實驗環境
5 實驗結果
5.1 RQ1: 我們提出的異常檢測模型與基準相比表現如何?
5.2 RQ2: 日誌序列中的順序和時間信息對異常檢測有多大影響?
5.3 RQ3: 不同類型的信息各自對異常檢測貢獻多少?
6 討論
7 有效性威脅
8 結論與參考文獻
\
3 可配置的基於 Transformer 的異常檢測方法
在本研究中,我們介紹了一種新穎的基於 Transformer 的異常檢測方法。該模型以日誌序列作為輸入來檢測異常。模型採用預訓練的 BERT 模型來嵌入日誌模板,使日誌訊息中的語義信息能夠被表示。這些嵌入與位置或時間編碼相結合,隨後輸入到 Transformer 模型中。這些組合信息在後續生成日誌序列級別表示時被利用,促進了異常檢測過程。我們設計的模型具有靈活性:輸入特徵是可配置的,因此我們可以使用或進行不同日誌數據特徵組合的實驗。此外,該模型被設計和訓練以處理不同長度的輸入日誌序列。在本節中,我們介紹我們的問題公式化和方法的詳細設計。
\ 3.1 問題公式化
我們遵循先前的工作[1],將任務公式化為二元分類任務,在其中我們以監督方式訓練我們提出的模型,將日誌序列分類為異常和正常。對於用於模型訓練和評估的樣本,我們採用靈活的分組方法來生成不同長度的日誌序列。詳細內容在第4節中介紹。
\ 3.2 日誌解析與日誌嵌入
在我們的工作中,我們通過使用預訓練語言模型編碼日誌模板,將日誌事件轉換為數值向量。為了獲取日誌模板,我們採用 Drain 解析器[24],它被廣泛使用並在大多數公共數據集上具有良好的解析性能[4]。我們使用預訓練的 Sentence-BERT 模型[25](即 all-MiniLML6-v2 [26])來嵌入由日誌解析過程生成的日誌模板。該預訓練模型是通過對比學習目標訓練的,並在各種 NLP 任務上達到了最先進的性能。我們利用這個預訓練模型創建一個表示,捕捉日誌訊息的語義信息,並為下游異常檢測模型說明日誌模板之間的相似性。模型的輸出維度為384。
\ 3.3 位置與時間編碼
原始的 Transformer 模型[27]採用位置編碼,使模型能夠利用輸入序列的順序。由於模型不包含遞歸和卷積,如果沒有位置編碼,模型將無法識別日誌序列。雖然一些研究表明,在處理序列數據時,沒有明確位置編碼的 Transformer 模型仍然與標準模型具有競爭力[28, 29],但重要的是要注意,輸入序列的任何排列都將產生相同的模型內部狀態。由於序列信息或時間信息可能是日誌序列中異常的重要指標,基於 Transformer 模型的先前工作利用標準位置編碼來注入序列中日誌事件或模板的順序[11, 12, 21],旨在檢測與錯誤執行順序相關的異常。然而,我們注意到,在一個常用的基於 Transformer 方法的複製實現中[5],實際上省略了位置編碼。據我們所知,沒有現有工作基於日誌的時間戳編碼時間信息用於異常檢測方法。在異常檢測任務中利用序列或時間信息的有效性尚不清楚。
\ 在我們提出的方法中,我們嘗試將序列和時間編碼納入 Transformer 模型,並探索序列和時間信息對異常檢測的重要性。具體來說,我們提出的方法有不同的變體,利用以下序列或時間編碼技術。然後將編碼添加到日誌表示中,作為 Transformer 結構的輸入。
\ 
3.3.1 相對時間流逝編碼 (RTEE)
我們提出這種時間編碼方法 RTEE,它簡單地用每個日誌事件的時間替代位置編碼中的位置索引。我們首先根據日誌序列中日誌事件的時間戳計算時間流逝。我們不使用日誌事件序列索引作為正弦和餘弦方程的位置,而是使用相對於日誌序列中第一個日誌事件的相對時間流逝來替代位置索引。表1顯示了日誌序列中時間間隔的示例。在示例中,我們有一個包含7個事件的日誌序列,時間跨度為7秒。從第一個事件到序列中每個事件的經過時間用於計算相應事件的時間編碼。與位置編碼類似,編碼是使用上述方程1計算的,並且在訓練過程中不會更新。
\ 
3.4 模型結構
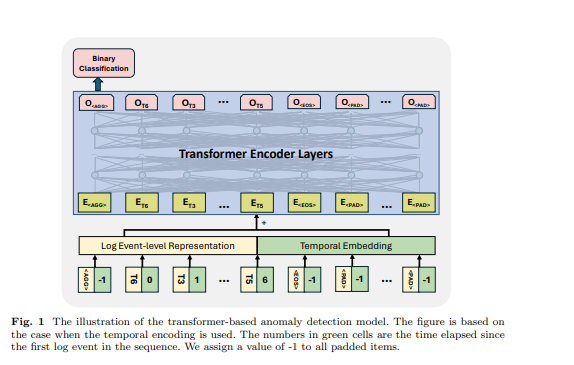
Transformer 是一種依賴自注意力機制來捕捉序列中輸入元素之間關係的神經網絡架構。基於 Transformer 的模型和框架已被許多先前的工作用於異常檢測任務[6, 11, 12, 21]。受先前工作的啟發,我們使用基於 Transformer 編碼器的模型進行異常檢測。我們設計的方法可以接受不同長度的日誌序列並生成序列級表示。為了實現這一點,我們在輸入日誌序列中使用了一些特定的標記,使模型能夠生成序列表示並識別填充標記和日誌序列的結束,這一靈感來自 BERT 模型[31]的設計。在輸入日誌序列中,我們使用了以下標記:放置在每個序列開始處,使模型能夠為整個序列生成聚合信息;添加在序列末尾,表示其完成;用於標記自監督訓練範式下的遮蔽標記;用於填充標記。這些特殊標記的嵌入是根據所使用的日誌表示的維度隨機生成的。圖1中顯示了一個示例,、和的時間流逝設置為-1。日誌事件級表示和位置或時間嵌入相加作為 Transformer 結構的輸入特徵。
\ 3.5 監督式二元分類 在這個訓練目標下,我們利用 Transformer 模型的第一個標記的輸出,同時忽略其他標記的輸出。這個第一個標記的輸出被設計為聚合整個輸入日誌序列的信息,類似於 BERT 模型的標記,它提供了標記序列的聚合表示。因此,我們將這個標記的輸出視為序列級表示。我們使用二元分類目標(即二元交叉熵損失)和這個表示來訓練模型。
\ 
:::info 作者:
- Xingfang Wu
- Heng Li
- Foutse Khomh
:::
:::info 本論文可在 Arxiv 上獲取,根據 CC by 4.0 Deed(Attribution 4.0 International)許可證。
:::
\
您可能也會喜歡

Bitcoin挖礦熱潮將伊朗變成「非法礦工的天堂」– CEO

股市波動對交易者構成挑戰
