جعل خطوط بياناتك أسرع بـ 5 أضعاف مع المعالجة المجمعة التكيفية
هل لديك استدعاءات ضخمة لنماذج اللغة الكبيرة في تدفق تحويل البيانات الخاص بك؟
CocoIndex قد يكون قادرًا على المساعدة. إنه مدعوم بمحرك Rust فائق الأداء ويدعم الآن المعالجة على دفعات التكيفية بشكل تلقائي. هذا حسّن الإنتاجية بمعدل ~5× (≈80% وقت تشغيل أسرع) لسير عمل الذكاء الاصطناعي الأصلية. والأفضل من ذلك كله، أنك لا تحتاج إلى تغيير أي كود لأن المعالجة على دفعات تحدث تلقائيًا، وتتكيف مع حركة المرور الخاصة بك وتحافظ على استخدام وحدات معالجة الرسومات بشكل كامل.
إليك ما تعلمناه أثناء بناء دعم المعالجة على دفعات التكيفية في Cocoindex.
ولكن أولاً، دعنا نجيب على بعض الأسئلة التي قد تكون في ذهنك.
لماذا تسرع المعالجة على دفعات من المعالجة؟
-
النفقات العامة الثابتة لكل استدعاء: تتكون من جميع الأعمال التحضيرية والإدارية المطلوبة قبل أن تبدأ الحوسبة الفعلية. تشمل الأمثلة إعداد إطلاق نواة وحدة معالجة الرسومات، والانتقالات من Python إلى C/C++، وجدولة المهام، وتخصيص الذاكرة وإدارتها، وحفظ السجلات التي يقوم بها الإطار. هذه المهام العامة مستقلة إلى حد كبير عن حجم المدخلات ولكن يجب دفعها بالكامل لكل استدعاء.
\
-
العمل المعتمد على البيانات: يتناسب هذا الجزء من الحوسبة مباشرة مع حجم وتعقيد المدخلات. يتضمن عمليات النقطة العائمة (FLOPs) التي يقوم بها النموذج، وحركة البيانات عبر تسلسلات الذاكرة، ومعالجة الرموز، وعمليات أخرى خاصة بالمدخلات. على عكس النفقات العامة الثابتة، تزداد هذه التكلفة بشكل متناسب مع حجم البيانات التي تتم معالجتها.
عندما تتم معالجة العناصر بشكل فردي، يتم تكبد النفقات العامة الثابتة بشكل متكرر لكل عنصر، مما يمكن أن يهيمن بسرعة على وقت التشغيل الإجمالي، خاصة عندما تكون الحوسبة لكل عنصر صغيرة نسبيًا. على النقيض من ذلك، فإن معالجة عناصر متعددة معًا في دفعات يقلل بشكل كبير من تأثير هذه النفقات العامة على كل عنصر. تسمح المعالجة على دفعات بتوزيع التكاليف الثابتة على العديد من العناصر، مع تمكين تحسينات الأجهزة والبرامج التي تحسن كفاءة العمل المعتمد على البيانات. تشمل هذه التحسينات استخدامًا أكثر فعالية لخطوط أنابيب وحدة معالجة الرسومات، واستخدام ذاكرة التخزين المؤقت بشكل أفضل، وعدد أقل من إطلاقات النواة، وكلها تساهم في زيادة الإنتاجية وتقليل زمن الاستجابة الإجمالي.
\
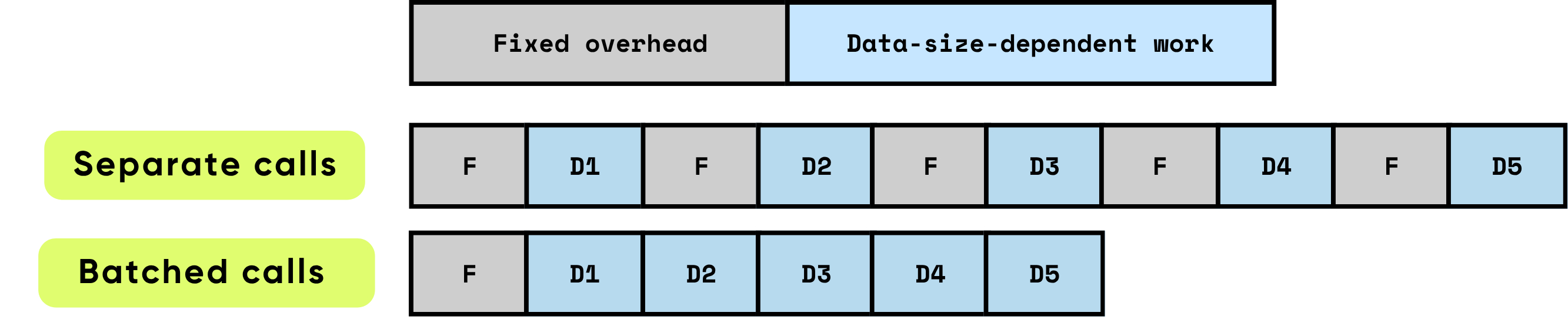
\ تحسن المعالجة على دفعات الأداء بشكل كبير من خلال تحسين كفاءة الحوسبة واستخدام الموارد. إنها توفر فوائد متعددة ومركبة:
\
-
استهلاك النفقات العامة لمرة واحدة: تحمل كل وظيفة أو استدعاء API نفقات عامة ثابتة — إطلاق نواة وحدة معالجة الرسومات، والانتقالات من Python إلى C/C++، وجدولة المهام، وإدارة الذاكرة، وحفظ سجلات الإطار. من خلال معالجة العناصر في دفعات، يتم توزيع هذه النفقات العامة على العديد من المدخلات، مما يقلل بشكل كبير من تكلفة كل عنصر ويلغي عمل الإعداد المتكرر.
\
-
تعظيم كفاءة وحدة معالجة الرسومات: تسمح الدفعات الأكبر لوحدة معالجة الرسومات بتنفيذ العمليات كمضاعفات مصفوفة متوازية كثيفة، يتم تنفيذها عادة كمضاعفة مصفوفة عامة (GEMM). يضمن هذا التعيين تشغيل الأجهزة بمعدل استخدام أعلى، مع الاستفادة الكاملة من وحدات الحوسبة المتوازية، وتقليل الدورات الخاملة، وتحقيق أقصى إنتاجية. تترك العمليات الصغيرة غير المعالجة على دفعات الكثير من وحدة معالجة الرسومات غير مستغلة، مما يهدر قدرة حسابية باهظة الثمن.
\
-
تقليل النفقات العامة لنقل البيانات: تقلل المعالجة على دفعات من تكرار عمليات نقل الذاكرة بين وحدة المعالجة المركزية (المضيف) ووحدة معالجة الرسومات (الجهاز). عدد أقل من عمليات المضيف إلى الجهاز (H2D) والجهاز إلى المضيف (D2H) يعني وقتًا أقل في نقل البيانات ووقتًا أكثر مخصصًا للحوسبة الفعلية. هذا أمر بالغ الأهمية لأنظمة الإنتاجية العالية، حيث غالبًا ما يصبح عرض النطاق الترددي للذاكرة هو العامل المحدد بدلاً من قوة الحوسبة الخام.
بالجمع بين هذه التأثيرات، تؤدي إلى تحسينات بمقدار عدة مرات في الإنتاجية. تحول المعالجة على دفعات العديد من العمليات الحسابية الصغيرة غير الفعالة إلى عمليات كبيرة محسنة للغاية تستغل بالكامل قدرات الأجهزة الحديثة. بالنسبة لأعباء عمل الذكاء الاصطناعي — بما في ذلك نماذج اللغة الكبيرة، ورؤية الكمبيوتر، ومعالجة البيانات في الوقت الفعلي — المعالجة على دفعات ليست مجرد تحسين؛ إنها ضرورية لتحقيق أداء قابل للتطوير على مستوى الإنتاج.
\
كيف تبدو المعالجة على دفعات لكود Python العادي
كود بدون معالجة على دفعات – بسيط ولكن أقل كفاءة
الطريقة الأكثر طبيعية لتنظيم خط الأنابيب هي معالجة البيانات قطعة بقطعة. على سبيل المثال، حلقة ذات طبقتين مثل هذه:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
هذا سهل القراءة والتفكير: كل جزء يتدفق مباشرة عبر خطوات متعددة.
المعالجة على دفعات يدويًا – أكثر كفاءة ولكن معقدة
يمكنك تسريعها من خلال المعالجة على دفعات، ولكن حتى أبسط إصدار "معالجة كل شيء على دفعة واحدة" يجعل الكود أكثر تعقيدًا بشكل كبير:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
علاوة على ذلك، فإن معالجة كل شيء دفعة واحدة عادة ما تكون غير مثالية لأن الخطوات التالية يمكن أن تبدأ فقط بعد الانتهاء من هذه الخطوة لجميع البيانات.
دعم المعالجة على دفعات في CocoIndex
يسد CocoIndex الفجوة ويتيح لك الحصول على أفضل ما في العالمين - الحفاظ على بساطة الكود الخاص بك باتباع التدفق الطبيعي، مع الحصول على الكفاءة من المعالجة على دفعات التي يوفرها وقت تشغيل CocoIndex.
لقد قمنا بالفعل بتمكين دعم المعالجة على دفعات للوظائف المدمجة التالية:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
لا يغير ذلك واجهة برمجة التطبيقات. سيعمل الكود الحالي الخاص بك دون أي تغيير - لا يزال يتبع التدفق الطبيعي، مع الاستمتاع بكفاءة المعالجة على دفعات.
بالنسبة للوظائف المخصصة، تمكين المعالجة على دفعات بسيط مثل:
- ضبط
batching=Trueفي مزين الوظيفة المخصصة. - تغيير الوسائط ونوع الإرجاع إلى
list.
على سبيل المثال، إذا كنت ترغب في إنشاء وظيفة مخصصة تستدعي واجهة برمجة تطبيقات لإنشاء ص
قد يعجبك أيضاً

بيع 5.3 مليون رمز من GeeFi (GEE) في اليوم الأول يثير مقارنات مع الزخم المبكر لـ Ripple (XRP) بين المحللين
انخفاض سعر الإيثريوم بنسبة 15% في أسبوع واحد — هل يمكن لصندوق ETH المُستثمر من BlackRock وقف هذا التراجع؟