

حل أكبر عائق في التجزئة ثلاثية الأبعاد
:::info المؤلفون:
(1) جورج تانج، معهد ماساتشوستس للتكنولوجيا;
(2) كريشنا مورثي جاتافالابهولا، معهد ماساتشوستس للتكنولوجيا;
(3) أنطونيو تورالبا، معهد ماساتشوستس للتكنولوجيا.
:::
جدول الروابط
الملخص والمقدمة
II. الخلفية
III. الطريقة
IV. التجارب
V. الخاتمة والمراجع
\ 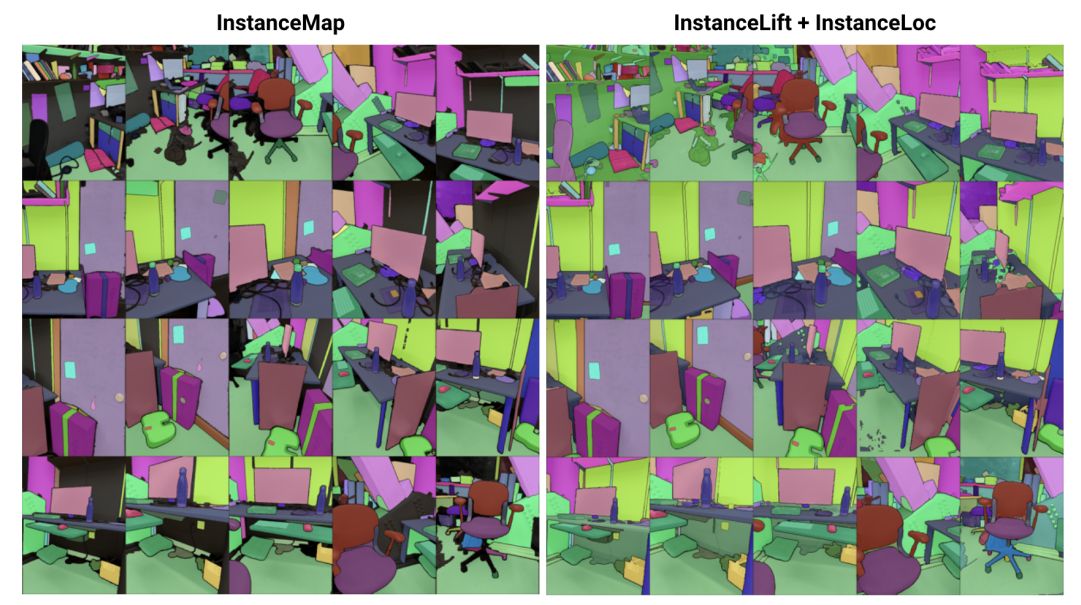
\ الملخص— نتناول مشكلة تعلم تمثيل مشهد ضمني للتجزئة الثلاثية الأبعاد للمثيل من تسلسل من صور RGB المضبوطة. نحو هذا، نقدم 3DIML، إطار عمل جديد يتعلم بكفاءة حقل تسمية يمكن عرضه من وجهات نظر جديدة لإنتاج أقنعة تجزئة مثيل متسقة الرؤية. يحسن 3DIML بشكل كبير أوقات التدريب والاستدلال للطرق القائمة على تمثيل المشهد الضمني الحالية. على عكس الفن السابق الذي يحسن حقلًا عصبيًا بطريقة ذاتية التعلم، مما يتطلب إجراءات تدريب معقدة وتصميم دالة خسارة، يستفيد 3DIML من عملية ذات مرحلتين. المرحلة الأولى، InstanceMap، تأخذ كمدخل أقنعة تجزئة ثنائية الأبعاد لتسلسل الصور التي تم إنشاؤها بواسطة نموذج تجزئة المثيل الأمامي، وتربط الأقنعة المقابلة عبر الصور بتسميات ثلاثية الأبعاد. ثم يتم استخدام أقنعة التسميات الزائفة المتسقة تقريبًا مع وجهة النظر في المرحلة الثانية، InstanceLift، للإشراف على تدريب حقل تسمية عصبي، والذي يستوفي المناطق التي فاتها InstanceMap ويحل الغموض. بالإضافة إلى ذلك، نقدم InstanceLoc، الذي يمكّن من تحديد موقع المثيل في الوقت الفعلي تقريبًا بالنظر إلى حقل تسمية مدرب ونموذج تجزئة صورة جاهز من خلال دمج المخرجات من كليهما. نقيّم 3DIML على تسلسلات من مجموعات بيانات Replica و ScanNet ونوضح فعالية 3DIML تحت افتراضات معتدلة لتسلسلات الصور. نحقق تسريعًا عمليًا كبيرًا مقارنة بطرق تمثيل المشهد الضمني الحالية مع جودة مماثلة، مما يظهر إمكاناتها لتسهيل فهم المشهد ثلاثي الأبعاد بشكل أسرع وأكثر فعالية.
I. المقدمة
تتطلب العوامل الذكية فهم المشهد على مستوى الكائن لتنفيذ إجراءات محددة السياق بفعالية مثل التنقل والتلاعب. في حين أن تجزئة الكائنات من الصور قد شهدت تقدمًا ملحوظًا مع نماذج قابلة للتطوير مدربة على مجموعات بيانات على نطاق الإنترنت [1]، [2]، لا يزال توسيع هذه القدرات إلى الإعداد ثلاثي الأبعاد يمثل تحديًا.
\ في هذا العمل، نتناول مشكلة تعلم تمثيل مشهد ثلاثي الأبعاد من صور ثنائية الأبعاد مضبوطة تقوم بتحليل المشهد الأساسي إلى مجموعة من الكائنات المكونة له. ركزت النهج الحالية لمعالجة هذه المشكلة على تدريب نماذج تجزئة ثلاثية الأبعاد غير محددة الفئة [3]، [4]، مما يتطلب كميات كبيرة من بيانات ثلاثية الأبعاد المشروحة، والعمل مباشرة على تمثيلات المشهد ثلاثية الأبعاد الصريحة (مثل سحابة النقاط). اقترحت فئة بديلة من النهج [5]، [6] بدلاً من ذلك رفع أقنعة التجزئة مباشرة من نماذج تجزئة المثيل الجاهزة إلى تمثيلات ثلاثية الأبعاد ضمنية، مثل حقول الإشعاع العصبية (NeRF) [7]، مما يمكنها من عرض أقنعة مثيل متسقة ثلاثية الأبعاد من وجهات نظر جديدة.
\ ومع ذلك، ظلت النهج القائمة على الحقل العصبي صعبة التحسين بشكل سيئ السمعة، مع استغراق [5] و [6] عدة ساعات للتحسين للصور ذات الدقة المنخفضة إلى المتوسطة (على سبيل المثال، 300 × 640). على وجه الخصوص، يتزايد Panoptic Lifting [5] بشكل مكعب مع زيادة عدد الكائنات في المشهد مما يمنع تطبيقه على المشاهد التي تحتوي على مئات الكائنات، بينما يتطلب Contrastively Lifting [6] إجراء تدريب متعدد المراحل معقد، مما يعيق التطبيق العملي للاستخدام في تطبيقات الروبوتات.
\ لهذه الغاية، نقترح 3DIML، تقنية فعالة لتعلم تجزئة المثيل المتسقة ثلاثية الأبعاد من صور RGB المضبوطة. يتكون 3DIML من مرحلتين: InstanceMap و InstanceLift. بالنظر إلى أقنعة المثيل ثنائية الأبعاد غير المتسقة المستخرجة من تسلسل RGB باستخدام نموذج تجزئة المثيل الأمامي [2]، ينتج InstanceMap سلسلة من أقنعة المثيل المتسقة مع وجهة النظر. للقيام بذلك، نقوم أولاً بربط الأقنعة عبر الإطارات باستخدام تطابقات النقاط الرئيسية بين أزواج الصور المتشابهة. ثم نستخدم هذه الارتباطات المحتملة الضوضاء للإشراف على حقل تسمية عصبي، InstanceLift، الذي يستغل البنية ثلاثية الأبعاد لاستيفاء التسميات المفقودة وحل الغموض. على عكس العمل السابق، الذي يتطلب تدريبًا متعدد المراحل وهندسة دالة خسارة إضافية، نستخدم خسارة عرض واحدة للإشراف على تسمية المثيل، مما يمكّن عملية التدريب من التقارب بشكل أسرع بكثير. يستغرق وقت التشغيل الإجمالي لـ 3DIML، بما في ذلك InstanceMap، 10-20 دقيقة، مقارنة بـ 3-6 ساعات للفن السابق.
\ بالإضافة إلى ذلك، نبتكر InstaLoc، وهو خط أنابيب تحديد موقع سريع يأخذ عرضًا جديدًا ويحدد موقع جميع المثيلات المجزأة في تلك الصورة (باستخدام نموذج تجزئة مثيل سريع [8]) من خلال الاستعلام بشكل متفرق عن حقل التسمية ودمج تنبؤات التسمية مع مناطق الصورة المستخرجة. أخيرًا، 3DIML معياري للغاية، ويمكننا بسهولة تبديل مكونات طريقتنا بأخرى أكثر أداءً عندما تصبح متاحة.
\ لتلخيص ذلك، مساهماتنا هي:
\ • نهج تعلم حقل عصبي فعال يقسم مشهدًا ثلاثي الأبعاد إلى كائناته المكونة
\ • خوارزمية تحديد موقع المثيل السريعة التي تدمج الاستعلامات المتفرقة إلى حقل التسمية المدرب مع نماذج تجزئة مثيل الصورة ذات الأداء لإنشاء أقنعة تجزئة مثيل متسقة ثلاثية الأبعاد
\ • تحسين وقت التشغيل العملي الإجمالي بمقدار 14-24× مقارنة بالفن السابق المقارن على وحدة معالجة رسومات واحدة (NVIDIA RTX 3090)
II. الخلفية
التجزئة ثنائية الأبعاد: أدى انتشار بنية محول الرؤية وزيادة حجم مجموعات بيانات الصور إلى سلسلة من نماذج تجزئة الصور المتطورة. يرفع كل من Panoptic و Contrastive Lifting أقنعة التجزئة البانورامية التي ينتجها Mask2Former [1] إلى ثلاثية الأبعاد من خلال تعلم حقل عصبي. نحو تجزئة المجموعة المفتوحة، يحقق segment anything (SAM) [2] أداءً غير مسبوق من خلال التدريب على مليار قناع على مدار 11 مليون صورة. يحسن HQ-SAM [9] من SAM للأقنعة الدقيقة. يقطر FastSAM [8] SAM في بنية CNN ويحقق أداءً مماثلاً مع كونه أسرع بمراتب. في هذا العمل، نستخدم GroundedSAM [10]، [11]، الذي يحسن SAM لإنتاج تجزئة على مستوى الكائن، بدلاً من أقنعة تجزئة على مستوى الجزء.
\ الحقول العصبية لتجزئة المثيل ثلاثية الأبعاد: NeRFs هي تمثيلات مشهد ضمنية يمكنها ترميز الهندسة المعقدة والدلالات والطرائق الأ
قد يعجبك أيضاً

ريبل برايم: أول شركة كريبتو تمتلك وسيط رئيسي متعدد الأصول عالمي

الأسهم الأمريكية تتفاعل مع تقرير التضخم لمؤشر أسعار المستهلك - داو جونز يقفز 350 نقطة
