

El estudio de ablación confirma la necesidad de tasas dinámicas para el rendimiento de RECKONING
Tabla de Enlaces
Resumen y 1. Introducción
-
Antecedentes
-
Método
-
Experimentos
4.1 Rendimiento de Razonamiento Multi-hop
4.2 Razonamiento con Distractores
4.3 Generalización al conocimiento del Mundo Real
4.4 Análisis de tiempo de ejecución
4.5 Memorización de Conocimiento
-
Trabajos Relacionados
-
Conclusión, Agradecimientos y Referencias
\ A. Conjunto de datos
B. Razonamiento en contexto con Distractores
C. Detalles de Implementación
D. Tasa de Aprendizaje Adaptativa
E. Experimentos con Modelos de Lenguaje Grandes
D Tasa de Aprendizaje Adaptativa
Trabajos anteriores [3, 4] muestran que una tasa de aprendizaje fija compartida entre pasos y parámetros no beneficia el rendimiento de generalización del sistema. En cambio, [3] recomienda aprender una tasa de aprendizaje para
\ 
\ 
\ cada capa de red y cada paso de adaptación en el bucle interno. Los parámetros de capa pueden aprender a ajustar las tasas de aprendizaje dinámicamente en cada paso. Para controlar la tasa de aprendizaje α en el bucle interno de manera adaptativa, definimos α como un conjunto de variables ajustables: α = {α0, α1, …αL}, donde L es el número de capas y para cada l = 0, …, L, αl es un vector con N elementos dado un número predefinido de pasos de bucle interno N. La ecuación de actualización del bucle interno se convierte entonces en
\ 
\ 
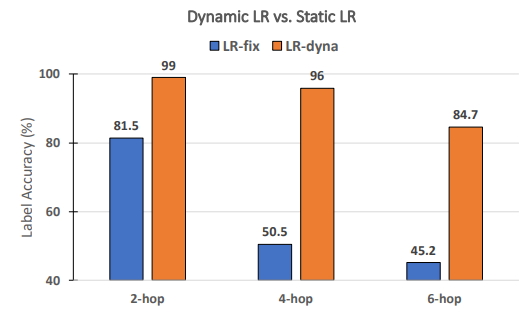
\ ¿Son necesarias las tasas de aprendizaje dinámicas para el rendimiento de RECKONING? Siguiendo trabajos previos sobre meta-aprendizaje [3, 4], aprendemos dinámicamente un conjunto de tasas de aprendizaje por paso y por capa para RECKONING. En este estudio de ablación, analizamos si las tasas de aprendizaje dinámicas para el bucle interno mejoran efectivamente el rendimiento de razonamiento del bucle externo. De manera similar, fijamos otras configuraciones experimentales y establecemos el número de pasos del bucle interno en 4. Como muestra la Figura 8, cuando se utiliza una tasa de aprendizaje estática (es decir, todas las capas y pasos del bucle interno comparten una tasa de aprendizaje constante), el rendimiento cae por un amplio margen (caída promedio del 34.2%). La caída de rendimiento se vuelve más significativa en preguntas que requieren más saltos de razonamiento (caída del 45.5% para 4 saltos y 39.5% para 6 saltos), lo que demuestra la importancia de usar una tasa de aprendizaje dinámica en el bucle interno de nuestro marco.
\ 
\
:::info Autores:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC BY 4.0 DEED.
:::
\
También te puede interesar

Acciones de Solana Company (HSDT): Se disparan mientras las tenencias de SOL superan los 2,3M con un rendimiento del 7%

El presidente de la Fed insinúa que el recorte de tasas de diciembre no está garantizado mientras Bitcoin cae a $110,000
