

L'étude d'ablation confirme la nécessité des taux dynamiques pour la performance de RECKONING
Table des liens
Abstrait et 1. Introduction
-
Contexte
-
Méthode
-
Expériences
4.1 Performance de raisonnement multi-étapes
4.2 Raisonnement avec distracteurs
4.3 Généralisation aux connaissances du monde réel
4.4 Analyse du temps d'exécution
4.5 Mémorisation des connaissances
-
Travaux connexes
-
Conclusion, Remerciements et Références
\ A. Ensemble de données
B. Raisonnement en contexte avec distracteurs
C. Détails d'implémentation
D. Taux d'apprentissage adaptatif
E. Expériences avec des grands modèles de langage
D Taux d'apprentissage adaptatif
Les travaux antérieurs [3, 4] montrent qu'un taux d'apprentissage fixe partagé entre les étapes et les paramètres ne bénéficie pas à la performance de généralisation du système. Au lieu de cela, [3] recommande d'apprendre un taux d'apprentissage pour
\ 
\ 
\ chaque couche de réseau et chaque étape d'adaptation dans la boucle interne. Les paramètres de couche peuvent apprendre à ajuster les taux d'apprentissage dynamiquement à chaque étape. Pour contrôler le taux d'apprentissage α dans la boucle interne de manière adaptative, nous définissons α comme un ensemble de variables ajustables : α = {α0, α1, …αL}, où L est le nombre de couches et pour chaque l = 0, …, L, αl est un vecteur avec N éléments étant donné un nombre d'étapes de boucle interne prédéfini N. L'équation de mise à jour de la boucle interne devient alors
\ 
\ 
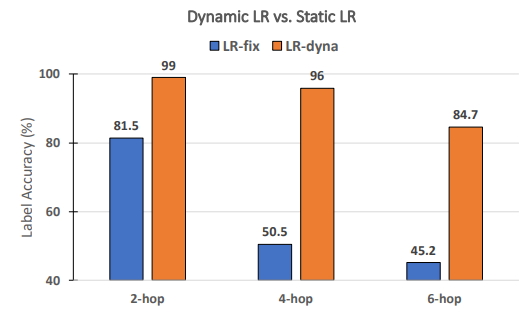
\ Les taux d'apprentissage dynamiques sont-ils nécessaires pour la performance de RECKONING? Suivant les travaux antérieurs sur le méta-apprentissage [3, 4], nous apprenons dynamiquement un ensemble de taux d'apprentissage par étape et par couche pour RECKONING. Dans cette étude d'ablation, nous analysons si les taux d'apprentissage dynamiques pour la boucle interne améliorent efficacement la performance de raisonnement de la boucle externe. De même, nous fixons d'autres paramètres expérimentaux et définissons le nombre d'étapes de la boucle interne à 4. Comme le montre la Figure 8, lors de l'utilisation d'un taux d'apprentissage statique (c'est-à-dire que toutes les couches et étapes de la boucle interne partagent un taux d'apprentissage constant), la performance chute considérablement (baisse moyenne de 34,2%). La baisse de performance devient plus significative pour les questions nécessitant plus d'étapes de raisonnement (baisse de 45,5% pour 4 étapes et 39,5% pour 6 étapes), démontrant l'importance d'utiliser un taux d'apprentissage dynamique dans la boucle interne de notre cadre.
\ 
\
:::info Auteurs:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info Cet article est disponible sur arxiv sous licence CC BY 4.0 DEED.
:::
\
Vous aimerez peut-être aussi

Action de Terrestrial Energy (IMSR) : Hausse lors de ses débuts au Nasdaq après une combinaison d'affaires de 292 millions de dollars

TeraWulf propose une offre privée de 500 millions de dollars en obligations convertibles de premier rang pour financer une entreprise d'IA soutenue par Google
