

Rendez vos pipelines de données 5 fois plus rapides avec le traitement par lots adaptatif
Avez-vous de nombreux appels LLM dans votre flux de transformation de données ?
CocoIndex pourrait vous aider. Il est alimenté par un moteur Rust ultra-performant et prend désormais en charge le traitement par lots adaptatif dès l'installation. Cela a amélioré le débit d'environ 5× (≈80% d'exécution plus rapide) pour les flux de travail natifs d'IA. Et le meilleur de tout, vous n'avez pas besoin de modifier votre code car le traitement par lots se fait automatiquement, s'adaptant à votre trafic et gardant les GPU pleinement utilisés.
Voici ce que nous avons appris en intégrant le support de traitement par lots adaptatif dans Cocoindex.
Mais d'abord, répondons à quelques questions que vous pourriez vous poser.
Pourquoi le traitement par lots accélère-t-il le traitement ?
-
Frais généraux fixes par appel : Cela comprend tout le travail préparatoire et administratif nécessaire avant que le calcul réel puisse commencer. Les exemples incluent la configuration du lancement du noyau GPU, les transitions Python vers C/C++, la planification des tâches, l'allocation et la gestion de la mémoire, et la comptabilité effectuée par le framework. Ces tâches générales sont largement indépendantes de la taille d'entrée mais doivent être payées intégralement pour chaque appel.
\
-
Travail dépendant des données : Cette partie du calcul évolue directement avec la taille et la complexité de l'entrée. Elle comprend les opérations en virgule flottante (FLOPs) effectuées par le modèle, le mouvement des données à travers les hiérarchies de mémoire, le traitement des tokens, et d'autres opérations spécifiques à l'entrée. Contrairement aux frais généraux fixes, ce coût augmente proportionnellement au volume de données traitées.
Lorsque les éléments sont traités individuellement, les frais généraux fixes sont encourus de manière répétée pour chaque élément, ce qui peut rapidement dominer le temps d'exécution total, surtout lorsque le calcul par élément est relativement petit. En revanche, le traitement de plusieurs éléments ensemble par lots réduit considérablement l'impact par élément de ces frais généraux. Le traitement par lots permet d'amortir les coûts fixes sur de nombreux éléments, tout en permettant des optimisations matérielles et logicielles qui améliorent l'efficacité du travail dépendant des données. Ces optimisations incluent une utilisation plus efficace des pipelines GPU, une meilleure utilisation du cache, et moins de lancements de noyaux, qui contribuent tous à un débit plus élevé et une latence globale plus faible.
\
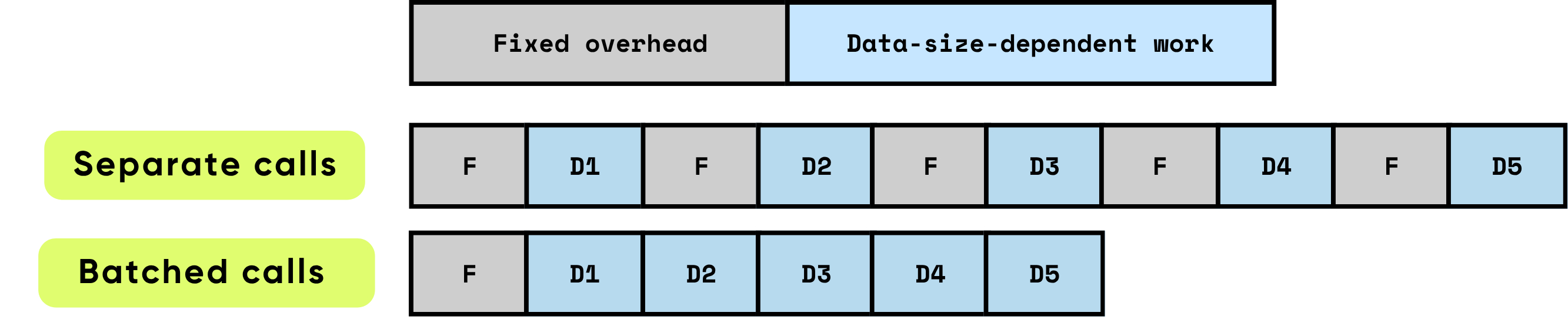
\ Le traitement par lots améliore significativement les performances en optimisant à la fois l'efficacité de calcul et l'utilisation des ressources. Il offre plusieurs avantages cumulatifs :
\
-
Amortissement des frais généraux uniques : Chaque fonction ou appel API comporte des frais généraux fixes — lancements de noyaux GPU, transitions Python vers C/C++, planification des tâches, gestion de la mémoire et comptabilité du framework. En traitant les éléments par lots, ces frais généraux sont répartis sur de nombreuses entrées, réduisant considérablement le coût par élément et éliminant le travail de configuration répété.
\
-
Maximisation de l'efficacité GPU : Des lots plus grands permettent au GPU d'exécuter des opérations sous forme de multiplications matricielles denses et hautement parallèles, communément implémentées comme Multiplication Matricielle Générale (GEMM). Ce mappage garantit que le matériel fonctionne à une utilisation plus élevée, exploitant pleinement les unités de calcul parallèles, minimisant les cycles d'inactivité et atteignant un débit maximal. Les petites opérations non traitées par lots laissent une grande partie du GPU sous-utilisée, gaspillant une capacité de calcul coûteuse.
\
-
Réduction des frais généraux de transfert de données : Le traitement par lots minimise la fréquence des transferts de mémoire entre CPU (hôte) et GPU (périphérique). Moins d'opérations Hôte-vers-Périphérique (H2D) et Périphérique-vers-Hôte (D2H) signifie moins de temps passé à déplacer des données et plus de temps consacré au calcul réel. C'est crucial pour les systèmes à haut débit, où la bande passante mémoire devient souvent le facteur limitant plutôt que la puissance de calcul brute.
Ensemble, ces effets conduisent à des améliorations de débit d'ordres de grandeur. Le traitement par lots transforme de nombreux calculs petits et inefficaces en opérations grandes et hautement optimisées qui exploitent pleinement les capacités du matériel moderne. Pour les charges de travail d'IA — y compris les grands modèles de langage, la vision par ordinateur et le traitement de données en temps réel — le traitement par lots n'est pas seulement une optimisation ; il est essentiel pour atteindre des performances évolutives de qualité production.
\
À quoi ressemble le traitement par lots pour du code Python normal
Code sans traitement par lots – simple mais moins efficace
La façon la plus naturelle d'organiser un pipeline est de traiter les données pièce par pièce. Par exemple, une boucle à deux niveaux comme celle-ci :
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
C'est facile à lire et à comprendre : chaque morceau passe directement par plusieurs étapes.
Traitement par lots manuel – plus efficace mais compliqué
Vous pouvez l'accélérer par le traitement par lots, mais même la version la plus simple "juste traiter tout en une fois" rend le code significativement plus compliqué :
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
De plus, traiter tout en une fois n'est généralement pas idéal car les étapes suivantes ne peuvent commencer qu'après que cette étape soit terminée pour toutes les données.
Support de traitement par lots de CocoIndex
CocoIndex comble le fossé et vous permet d'obtenir le meilleur des deux mondes – conserver la simplicité de votre code en suivant le flux naturel, tout en obtenant l'efficacité du traitement par lots fourni par l'exécution de CocoIndex.
Nous avons déjà activé le support de traitement par lots pour les fonctions intégrées suivantes :
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
Cela ne change pas l'API. Votre code existant fonctionnera sans aucun changement – suivant toujours le flux naturel, tout en profitant de l'efficacité du traitement par lots.
Pour les fonctions personnalisées, activer le traitement par lots est aussi simple que :
- Définir
batching=Truedans le décorateur de fonction personnalisée. - Changer les arguments et le type de retour en
list.
Par exemple, si vous voulez créer une fonction personnalisée qui appelle une API pour créer des vignettes d'images.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip Consultez la documentation sur le traitement par lots pour plus de détails.
:::
Comment CocoIndex traite par lots
Approches communes
Le traitement par lots fonctionne en collectant les requêtes entrantes dans une file d'attente et en décidant du bon moment pour les vider en un seul lot. Ce timing est crucial — si vous le faites correctement, vous équilibrez le débit, la latence et l'utilisation des ressources en même temps.
Deux politiques de traitement par lots largement utilisées dominent le paysage :
- Traitement par lots basé sur le temps (vider tous les W millisecondes) : Dans cette approche, le système vide toutes les requêtes arrivées dans une fenêtre fixe de W millisecondes.
-
Avantages : Le temps d'attente maximum pour toute requête est prévisible, et l'implémentation est simple. Cela garantit que même pendant un trafic faible, les requêtes ne resteront pas indéfiniment dans la file d'attente.
-
Inconvénients : Pendant les périodes de trafic clairsemé, les requêtes inactives s'accumulent lentement, ajoutant de la latence pour les arrivées précoces. De plus, la fenêtre optimale W varie souvent avec les caractéristiques de la charge de travail, nécessitant un réglage minutieux pour trouver le bon équilibre entre latence et débit.
\
- Traitement par lots basé sur la taille (vider quand K éléments sont en file d'attente) : Ici, un lot est déclenché une fois que la file d'attente atteint un nombre prédéfini d'éléments, K.
- Avantages : La taille du lot est prévisible, ce qui simplifie la gestion de la mémoire et la conception du système. Il est facile de raisonner sur les ressources que chaque lot consommera.
- Inconvénients : Lorsque le trafic est léger, les requêtes peuvent rester dans la file d'attente pendant une période prolongée, augmentant la latence pour les premiers éléments arrivés. Comme le traitement par lots basé sur le temps, le K optimal dépend des modèles de charge de travail, nécessitant un réglage empirique.
De nombreux systèmes haute performance adoptent une approche hybride : ils vident un lot lorsque soit la fenêtre de temps W expire, soit la file d'attente atteint la taille K — selon ce qui se produit en premier. Cette stratégie capture les avantages des deux méthodes, améliorant la réactivité pendant le trafic clairsemé tout en maintenant des tailles de lots efficaces pendant les pics de charge.
Malgré cela, le traitement par lots implique toujours des paramètres réglables et des compromis. Les modèles de trafic, les caractéristiques de la charge de travail et les contraintes du système influencent tous les paramètres idéaux. Atteindre des performances optimales nécessite souvent de surveiller, profiler et ajuster dynamiquement ces paramètres pour s'aligner sur les conditions en temps réel.
L'approche de CocoIndex
Niveau framework : adaptatif, sans bouton
CocoIndex implémente un mécanisme de traitement par lots simple et naturel qui s'adapte automatiquement à la charge de requêtes entrantes. Le processus fonctionne comme suit :
\
- Mise en file d'attente continue : Pendant que le lot actuel est traité sur le périphérique (par exemple, GPU), toutes les nouvelles requêtes entrantes ne sont pas immédiatement traitées. Au lieu de cela, elles sont mises en file d'attente. Cela permet au système d'accumuler du travail sans interrompre le calcul en cours.
- Fenêtre de lot automatique : Lorsque le lot actuel est terminé, CocoIndex prend immédiatement toutes les requêtes qui se sont accumulées dans la file d'attente et les traite comme le prochain lot. Cet ensemble de requêtes forme la nouvelle fenêtre de lot
Vous aimerez peut-être aussi

Tether soutient Parfin pour étendre l'utilisation institutionnelle d'USD₮ en Amérique latine

Ray Dalio réaffirme son scepticisme envers le Bitcoin, dit qu'il ne maintient toujours qu'une allocation de 1%
