

Matting Robusto Guidato da Maschera: Gestione di Input con Rumore e Versatilità degli Oggetti
Tabella dei Collegamenti
Astratto e 1. Introduzione
-
Lavori Correlati
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Instance Matting Datasets
4.1. Image Instance Matting e 4.2. Video Instance Matting
-
Esperimenti
5.1. Pre-training su dati immagine
5.2. Training su dati video
-
Discussione e Riferimenti
\ Materiale Supplementare
-
Dettagli architettura
-
Image matting
8.1. Generazione e preparazione del dataset
8.2. Dettagli training
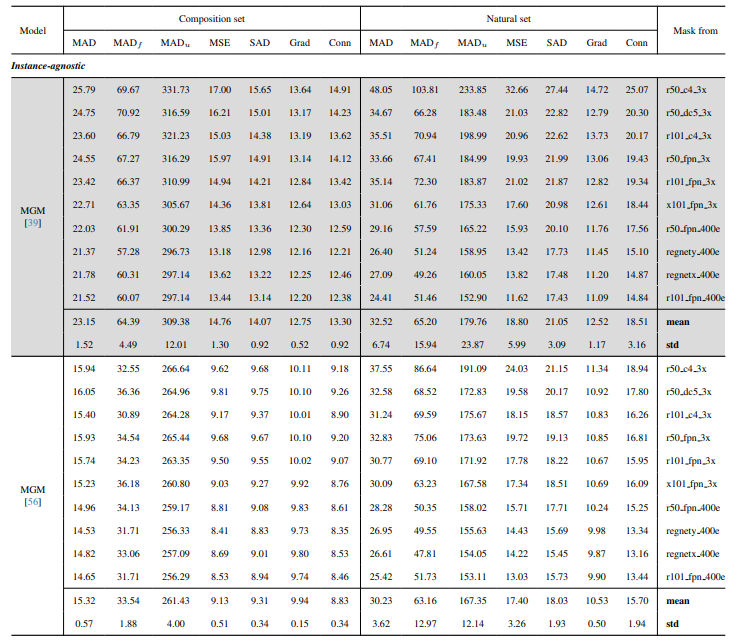
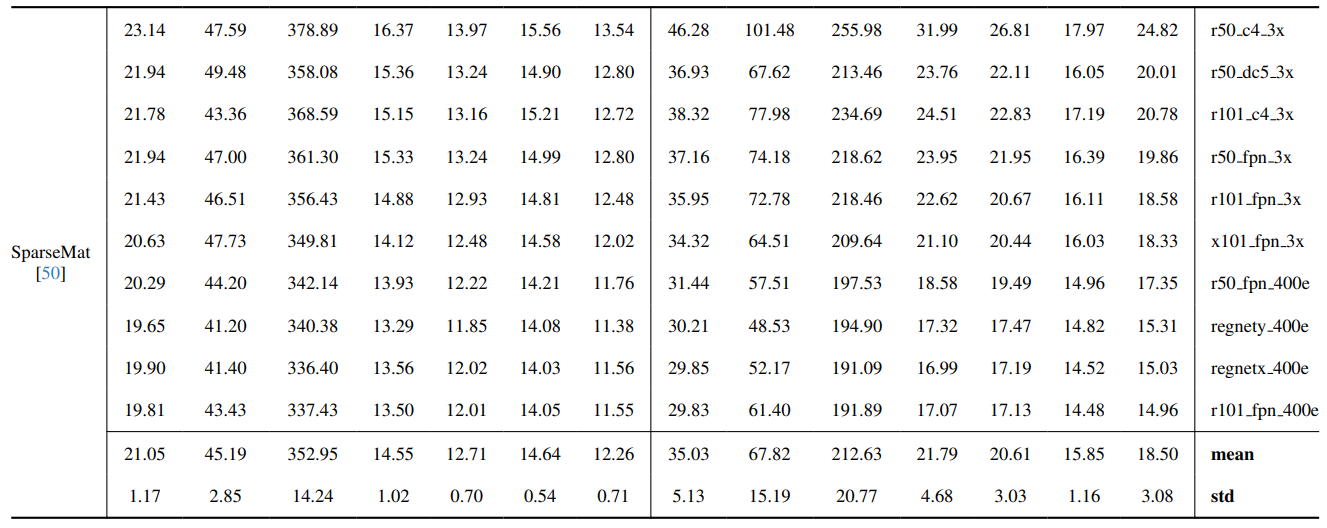
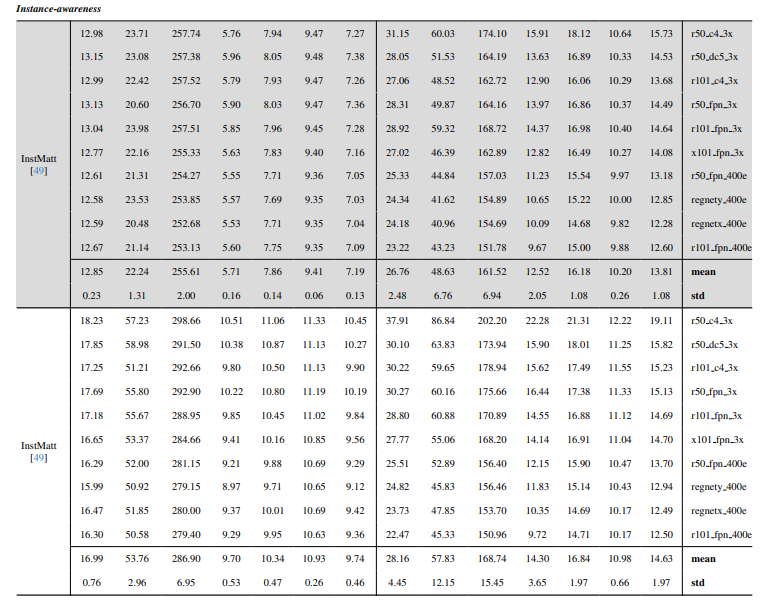
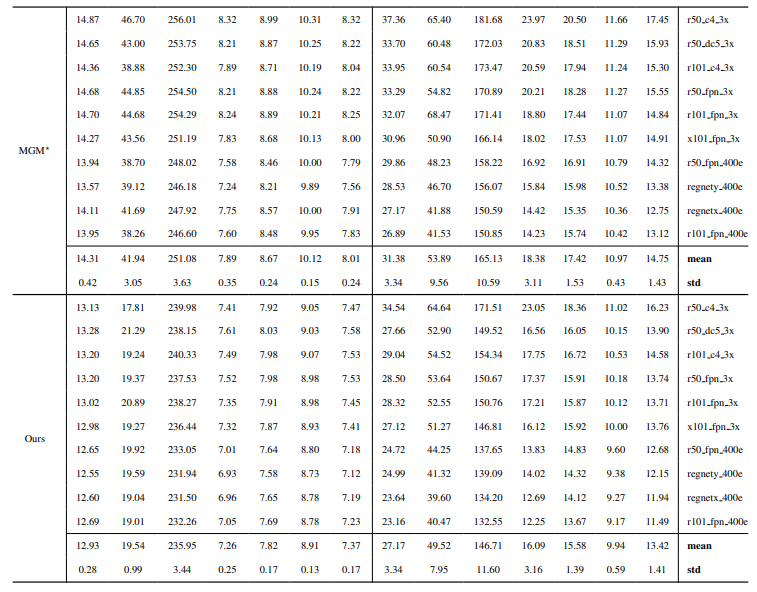
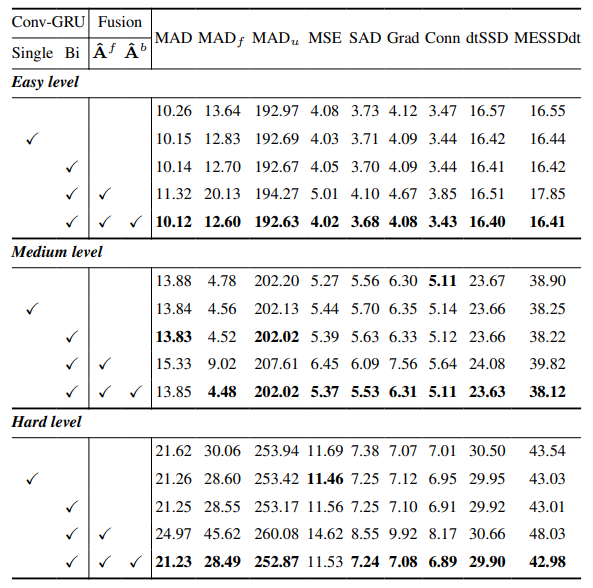
8.3. Dettagli quantitativi
8.4. Ulteriori risultati qualitativi su immagini naturali
-
Video matting
9.1. Generazione del dataset
9.2. Dettagli training
9.3. Dettagli quantitativi
9.4. Ulteriori risultati qualitativi
8.4. Ulteriori risultati qualitativi su immagini naturali
La Fig. 13 mostra le prestazioni del nostro modello in scenari complessi, in particolare nel rendering accurato delle regioni dei capelli. Il nostro framework supera costantemente MGM⋆ nella conservazione dei dettagli, specialmente nelle interazioni complesse tra istanze. In confronto con InstMatt, il nostro modello esibisce una separazione delle istanze superiore e un'accuratezza dei dettagli nelle regioni ambigue.
\ La Fig. 14 e la Fig. 15 illustrano le prestazioni del nostro modello e dei lavori precedenti in casi estremi che coinvolgono istanze multiple. Mentre MGM⋆ fatica con il rumore e l'accuratezza in scenari con istanze dense, il nostro modello mantiene un'alta precisione. InstMatt, senza dati di training aggiuntivi, mostra limitazioni in questi contesti complessi.
\ La robustezza del nostro approccio guidato da maschera è ulteriormente dimostrata nella Fig. 16. Qui, evidenziamo le sfide affrontate dalle varianti MGM e SparseMat nel predire le parti mancanti negli input delle maschere, che il nostro modello affronta. Tuttavia, è importante notare che il nostro modello non è progettato come rete di segmentazione delle istanze umane. Come mostrato nella Fig. 17, il nostro framework aderisce alla guida di input, garantendo una previsione precisa dell'alpha matte anche con istanze multiple nella stessa maschera.
\ Infine, la Fig. 12 e la Fig. 11 enfatizzano le capacità di generalizzazione del nostro modello. Il modello estrae accuratamente sia i soggetti umani che altri oggetti dagli sfondi, mostrando la sua versatilità attraverso vari scenari e tipi di oggetti.
\ Tutti gli esempi sono immagini Internet senza ground-truth e la maschera da r101fpn400e viene utilizzata come guida.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autori:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Questo documento è disponibile su arxiv sotto licenza CC by 4.0 Deed (Attribution 4.0 International).
:::
\
Potrebbe anche piacerti

XRP Affronta un Potenziale Calo del Prezzo Senza Supporto Chiave

L'Adozione della Rete Sui si Espande con la Spinta degli ETF: SUI Punta a un Breakout Sopra $1,79
