

Trích xuất Ngữ nghĩa Mở: Quy trình Grounded-SAM, CLIP và DINOv2
Bảng liên kết
Tóm tắt và 1 Giới thiệu
-
Các công trình liên quan
2.1. Điều hướng bằng thị giác và ngôn ngữ
2.2. Hiểu cảnh ngữ nghĩa và phân đoạn thể hiện
2.3. Tái tạo cảnh 3D
-
Phương pháp luận
3.1. Thu thập dữ liệu
3.2. Thông tin ngữ nghĩa tập mở từ hình ảnh
3.3. Tạo biểu diễn 3D tập mở
3.4. Điều hướng dựa trên ngôn ngữ
-
Thí nghiệm
4.1. Đánh giá định lượng
4.2. Kết quả định tính
-
Kết luận và công việc tương lai, Tuyên bố công khai và Tài liệu tham khảo
3.2. Thông tin ngữ nghĩa tập mở từ hình ảnh
\ 3.2.1. Phát hiện mặt nạ ngữ nghĩa và thể hiện tập mở
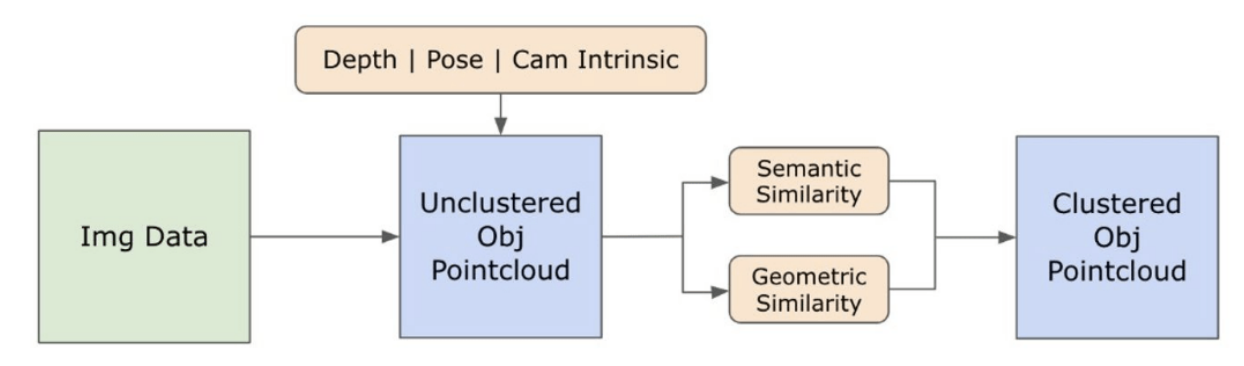
\ Mô hình Segment Anything (SAM) [21] mới được phát hành đã đạt được sự phổ biến đáng kể trong giới nghiên cứu và các chuyên gia công nghiệp nhờ khả năng phân đoạn tiên tiến. Tuy nhiên, SAM có xu hướng tạo ra quá nhiều mặt nạ phân đoạn cho cùng một đối tượng. Chúng tôi áp dụng mô hình Grounded-SAM [32] cho phương pháp của mình để giải quyết vấn đề này. Quá trình này bao gồm việc tạo ra một tập hợp các mặt nạ trong ba giai đoạn, như được minh họa trong Hình 2. Ban đầu, một tập hợp các nhãn văn bản được tạo ra bằng mô hình Recognizing Anything (RAM) [33]. Sau đó, các hộp giới hạn tương ứng với các nhãn này được tạo ra bằng mô hình Grounding DINO [25]. Hình ảnh và các hộp giới hạn sau đó được đưa vào SAM để tạo ra các mặt nạ phân đoạn không phân biệt lớp cho các đối tượng được nhìn thấy trong hình ảnh. Chúng tôi cung cấp một giải thích chi tiết về phương pháp này dưới đây, phương pháp này giảm thiệu hiệu quả vấn đề phân đoạn quá mức bằng cách kết hợp các hiểu biết ngữ nghĩa từ RAM và Grounding-DINO.
\ Mô hình RAM) [33] xử lý hình ảnh RGB đầu vào để tạo ra nhãn ngữ nghĩa của đối tượng được phát hiện trong hình ảnh. Đây là một mô hình nền tảng mạnh mẽ cho việc gắn thẻ hình ảnh, thể hiện khả năng zero-shot đáng chú ý trong việc xác định chính xác các danh mục phổ biến khác nhau. Đầu ra của mô hình này liên kết mỗi hình ảnh đầu vào với một tập hợp các nhãn mô tả các danh mục đối tượng trong hình ảnh. Quá trình bắt đầu bằng việc truy cập hình ảnh đầu vào và chuyển đổi nó sang không gian màu RGB, sau đó được điều chỉnh kích thước để phù hợp với yêu cầu đầu vào của mô hình, và cuối cùng chuyển đổi nó thành một tensor, làm cho nó tương thích với việc phân tích bởi mô hình. Sau đó, mô hình RAM tạo ra các nhãn, hoặc thẻ, mô tả các đối tượng hoặc tính năng khác nhau có trong hình ảnh. Một quá trình lọc được sử dụng để tinh chỉnh các nhãn được tạo ra, bao gồm việc loại bỏ các lớp không mong muốn từ các nhãn này. Cụ thể, các thẻ không liên quan như "tường", "sàn", "trần nhà" và "văn phòng" bị loại bỏ, cùng với các lớp được xác định trước khác được coi là không cần thiết cho bối cảnh của nghiên cứu. Ngoài ra, giai đoạn này cho phép bổ sung tập hợp nhãn với bất kỳ lớp cần thiết nào không được phát hiện ban đầu bởi mô hình RAM. Cuối cùng, tất cả thông tin liên quan được tổng hợp thành một định dạng có cấu trúc. Cụ thể, mỗi hình ảnh được phân loại trong từ điển img_dict, ghi lại đường dẫn của hình ảnh cùng với tập hợp các nhãn được tạo ra, đảm bảo một kho lưu trữ dữ liệu dễ tiếp cận cho phân tích tiếp theo.
\ Sau khi gắn thẻ hình ảnh đầu vào với các nhãn được tạo ra, quy trình tiếp tục bằng cách gọi mô hình Grounding DINO [25]. Mô hình này chuyên về việc gắn các cụm từ văn bản vào các vùng cụ thể trong hình ảnh, phác thảo hiệu quả các đối tượng mục tiêu bằng các hộp giới hạn. Quá trình này xác định và định vị không gian các đối tượng trong hình ảnh, đặt nền tảng cho các phân tích chi tiết hơn. Sau khi xác định và định vị các đối tượng thông qua các hộp giới hạn, Segment Anything Model (SAM) [21] được sử dụng. Chức năng chính của mô hình SAM là tạo ra các mặt nạ phân đoạn cho các đối tượng trong các hộp giới hạn này. Bằng cách này, SAM cô lập các đối tượng riêng lẻ, cho phép phân tích chi tiết hơn và cụ thể cho từng đối tượng bằng cách tách hiệu quả các đối tượng khỏi nền và khỏi nhau trong hình ảnh.
\ Tại thời điểm này, các thể hiện của đối tượng đã được xác định, định vị và cô lập. Mỗi đối tượng được xác định với các chi tiết khác nhau, bao gồm tọa độ hộp giới hạn, một thuật ngữ mô tả cho đối tượng, điểm số khả năng hoặc độ tin cậy về sự tồn tại của đối tượng được biểu thị bằng logits, và mặt nạ phân đoạn. Hơn nữa, mỗi đối tượng được liên kết với các tính năng nhúng CLIP và DINOv2, chi tiết về các tính năng này được trình bày trong phần tiếp theo.
\ 3.2.2. Trích xuất nhúng ngữ nghĩa
\ Để cải thiện sự hiểu biết của chúng tôi về các khía cạnh ngữ nghĩa của các thể hiện đối tượng đã được phân đoạn và che mặt trong hình ảnh của chúng tôi, chúng tôi sử dụng hai mô hình, CLIP [9] và DINOv2 [10], để lấy các biểu diễn đặc trưng từ các hình ảnh được cắt của mỗi đối tượng. Một mô hình được đào tạo độc quyền với CLIP đạt được sự hiểu biết ngữ nghĩa mạnh mẽ về hình ảnh nhưng không thể phân biệt độ sâu và các chi tiết phức tạp trong những hình ảnh đó. Mặt khác, DINOv2 thể hiện hiệu suất vượt trội trong nhận thức độ sâu và xuất sắc trong việc xác định các mối quan hệ cấp pixel tinh tế trên các hình ảnh. Là một Vision Transformer tự giám sát, DINOv2 có thể trích xuất các chi tiết đặc trưng tinh tế mà không cần dựa vào dữ liệu được chú thích, làm cho nó đặc biệt hiệu quả trong việc xác định các mối quan hệ không gian và phân cấp trong hình ảnh. Ví dụ, trong khi mô hình CLIP có thể gặp khó khăn trong việc phân biệt giữa hai chiếc ghế có màu sắc khác nhau, chẳng hạn như đỏ và xanh lá cây, khả năng của DINOv2 cho phép các phân biệt như vậy được thực hiện rõ ràng. Để kết luận, các mô hình này nắm bắt cả đặc điểm ngữ nghĩa và trực quan của các đối tượng, sau đó được sử dụng để so sánh tương đồng trong không gian 3D.
\ 
\ Một tập hợp các bước tiền xử lý được thực hiện để xử lý hình ảnh với mô hình DINOv2. Các bước này bao gồm điều chỉnh kích thước, cắt trung tâm, chuyển đổi hình ảnh thành tensor và chuẩn hóa các hình ảnh được cắt được phác thảo bởi các hộp giới hạn. Hình ảnh đã xử lý sau đó được đưa vào mô hình DINOv2 cùng với các nhãn được xác định bởi mô hình RAM để tạo ra các tính năng nhúng DINOv2. Mặt khác, khi làm việc với mô hình CLIP, bước tiền xử lý liên quan đến việc chuyển đổi hình ảnh được cắt thành định dạng tensor tương thích với CLIP, tiếp theo là tính toán các tính năng nhúng. Các nhúng này rất quan trọng vì chúng bao gồm các thuộc tính trực quan và ngữ nghĩa của các đối tượng, điều này rất quan trọng cho sự hiểu biết toàn diện về các đối tượng trong cảnh. Các nhúng này trải qua quá trình chuẩn hóa dựa trên chuẩn L2 của chúng, điều chỉnh vector đặc trưng thành độ dài đơn vị tiêu chuẩn. Bước chuẩn hóa này cho phép so sánh nhất quán và công bằng trên các hình ảnh khác nhau.
\ Trong giai đoạn thực hiện của giai đoạn này, chúng tôi lặp lại qua mỗi hình ảnh trong dữ liệu của chúng tôi và thực hiện các thủ tục tiếp theo:
\ (1) Hình ảnh được cắt đến vùng quan tâm bằng cách sử dụng tọa độ hộp giới hạn được cung cấp bởi mô hình Grounding DINO, cô lập đối tượng để phân tích chi tiết.
\ (2) Tạo ra các nhúng DINOv2 và CLIP cho hình ảnh được cắt.
\ (3) Cuối cùng, các nhúng được lưu trữ lại cùng với các mặt nạ từ phần trước.
\ Với các bước này hoàn thành, chúng tôi hiện có các biểu diễn đặc trưng chi tiết cho mỗi đối tượng, làm phong phú bộ dữ liệu của chúng tôi để phân tích và ứng dụng thêm.
\
:::info Tác giả:
(1) Laksh Nanwani, Viện Công nghệ Thông tin Quốc tế, Hyderabad, Ấn Độ; tác giả này đóng góp bình đẳng cho công trình này;
(2) Kumaraditya Gupta, Viện Công nghệ Thông tin Quốc tế, Hyderabad, Ấn Độ;
(3) Aditya Mathur, Viện Công nghệ Thông tin Quốc tế, Hyderabad, Ấn Độ; tác giả này đóng góp bình đẳng cho công trình này;
(4) Swayam Agrawal, Viện Công nghệ Thông tin Quốc tế, Hyderabad, Ấn Độ;
(5) A.H. Abdul Hafez, Đại học Hasan Kalyoncu, Sahinbey, Gaziantep, Thổ Nhĩ Kỳ;
(6) K. Madhava Krishna, Viện Công nghệ Thông tin Quốc tế, Hyderabad, Ấn Độ.
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\
Có thể bạn cũng thích
Các nhà đầu tư XRP lạc quan khi tâm lý xã hội chuyển biến tích cực
![[Hai mũi nhọn] Số phận đã khiến tôi kết thúc với cùng một kiểu phụ nữ mỗi lần?](https://www.rappler.com/tachyon/2025/12/two-pronged-2-Factor-Authentication-relationship.jpg)
[Hai mũi nhọn] Số phận đã khiến tôi kết thúc với cùng một kiểu phụ nữ mỗi lần?
