

DiverGen 使大规模实例分割训练更有效
:::info 作者:
(1) 范成祥,来自中国浙江大学,贡献相同;
(2) 朱慕之,来自中国浙江大学,贡献相同;
(3) 陈浩,中国浙江大学 (haochen.cad@zju.edu.cn);
(4) 刘洋,中国浙江大学;
(5) 吴伟佳,中国浙江大学;
(6) 张华琦,vivo移动通信有限公司;
(7) 沈春华,中国浙江大学 (chunhuashen@zju.edu.cn)。
:::
链接目录
摘要和1 引言
-
相关工作
-
我们提出的DiverGen
3.1. 数据分布分析
3.2. 生成数据多样性增强
3.3. 生成流程
-
实验
4.1. 设置
4.2. 主要结果
4.3. 消融研究
-
结论、致谢和参考文献
\ 附录
A. 实现细节
B. 可视化
摘要
实例分割任务对数据需求量大,随着模型容量的增加,数据规模对提高准确性变得至关重要。如今大多数实例分割数据集需要昂贵的人工标注,限制了其数据规模。在这类数据上训练的模型容易在训练集上过拟合,尤其是对于那些稀有类别。虽然最近的工作已经深入研究利用生成模型创建合成数据集进行数据增强,但这些方法并未有效利用生成模型的全部潜力。
\ 为解决这些问题,我们引入了一种更高效的策略来构建用于数据增强的生成数据集,称为DiverGen。首先,我们从分布差异的角度解释了生成数据的作用。我们研究了不同数据对模型学习分布的影响。我们认为生成数据可以扩展模型可以学习的数据分布,从而减轻过拟合。此外,我们发现生成数据的多样性对提高模型性能至关重要,并通过各种策略增强它,包括类别多样性、提示多样性和生成模型多样性。通过这些策略,我们可以将数据规模扩展到数百万,同时保持模型性能提升的趋势。在LVIS数据集上,DiverGen显著优于强大的模型X-Paste,在所有类别上实现了+1.1框AP和+1.1掩码AP,在稀有类别上实现了+1.9框AP和+2.5掩码AP。我们的代码可在https://github.com/aim-uofa/DiverGen获取。
1. 引言
实例分割[2, 4, 9]是计算机视觉中具有挑战性的任务之一,需要预测图像中实例的掩码和类别,这是众多视觉应用的基础。随着模型学习能力的提高,对训练数据的需求也在增加。然而,当前用于实例分割的数据集严重依赖人工标注,这既耗时又昂贵,数据集规模无法满足模型的训练需求。尽管最近出现了自动标注的数据集SA-1B[12],但它缺乏类别标注,无法满足实例分割的要求。同时,生成模型的持续发展大大提高了生成样本的可控性和真实性。例如,最近的文本到图像扩散模型[22, 24]可以生成与输入提示相对应的高质量图像。因此,当前方法[27, 28, 34]使用生成模型进行数据增强,通过生成数据集来补充模型在真实数据集上的训练并提高模型性能。虽然当前方法已经提出了各种策略使生成数据能够提升模型性能,但仍存在一些限制:1) 现有方法尚未充分利用生成模型的潜力。首先,一些方法[34]不仅使用生成数据,还需要从互联网爬取图像,这对获取大规模数据是一个重大挑战。同时,从互联网爬取的数据内容不可控,需要额外检查。其次,现有方法没有充分利用生成模型的可控性。当前方法通常采用手动设计的模板来构建提示,限制了生成模型的潜在输出。2) 现有方法[27, 28]通常从类别不平衡或数据稀缺的角度解释生成数据的作用,而没有考虑真实世界数据和生成数据之间的差异。此外,这些方法通常只在真实样本数量有限的情况下显示出改进的模型性能,而对现有大规模真实数据集(如LVIS[8])上生成数据的有效性没有进行彻底调查。
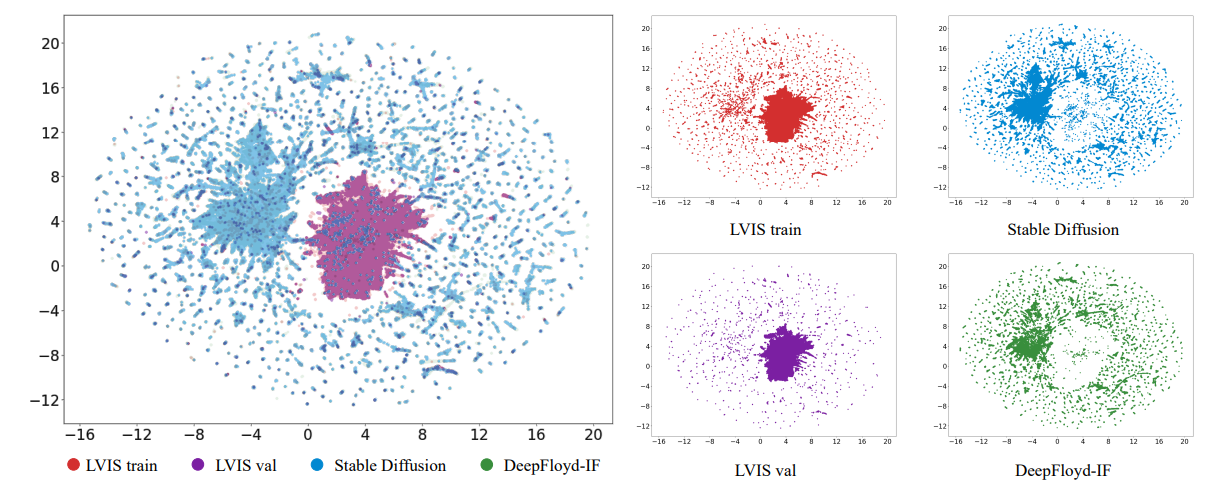
\ 在本文中,我们首先从分布差异的角度探讨生成数据的作用,解决两个主要问题:1) 为什么生成数据增强能提高模型性能? 2) 什么类型的生成数据有利于提高模型性能?首先,我们发现有限真实训练数据的模型学习分布与真实世界数据分布之间存在差异。我们对数据进行可视化,发现与真实世界数据相比,生成数据可以扩展模型可以学习的数据分布。此外,我们发现添加生成数据的作用是减轻真实训练数据的偏差,有效缓解对训练数据的过拟合。其次,我们发现生成数据的分布与真实世界数据分布之间也存在差异。如果这些差异处理不当,就无法充分利用生成模型的潜力。通过进行多项实验,我们发现使用多样化的生成数据使模型能够更好地适应这些差异,提高模型性能。
\ 基于上述分析,我们提出了一种增强数据多样性的高效策略,即生成数据多样性增强。我们设计了各种多样性增强策略,从类别多样性、提示多样性和生成模型多样性的角度增加数据多样性。对于类别多样性,我们观察到使用覆盖所有类别的生成数据训练的模型比使用部分类别训练的模型更能适应分布差异。因此,我们不仅引入了LVIS[8]中的类别,还引入了ImageNet-1K[23]中的额外类别,以增强数据生成中的类别多样性,从而增强模型对分布差异的适应性。对于提示多样性,我们发现随着生成数据集规模的增加,手动设计的提示无法扩展到相应的水平,限制了生成模型输出图像的多样性。因此,我们设计了一套多样化的提示生成策略,使用大型语言模型(如ChatGPT)进行提示生成,要求大型语言模型在约束条件下输出最大程度多样化的提示。通过结合手动设计的提示和ChatGPT设计的提示,我们有效丰富了提示多样性,进一步提高了生成数据多样性。对于生成模型多样性,我们发现来自不同生成模型的数据也表现出分布差异。在训练过程中让模型接触来自不同生成模型的数据可以增强对不同分布的适应性。因此,我们分别使用Stable Diffusion[22]和DeepFloyd-IF[24]为所有类别生成图像,并在训练过程中混合这两种类型的数据以增加数据多样性。
\ 同时,我们优化了数据生成工作流程,提出了一个由实例生成、实例标注、实例过滤和实例增强组成的四阶段生成流程。在实例生成阶段,我们采用我们提出的生成数据多样性增强来提高数据多样性,产生多样化的原始数据。在实例标注阶段,我们引入了一种称为SAM-background的标注策略。该策略通过使用背景点作为SAM[12]的输入提示,获得高质量的标注,从而获得原始数据的标注。在实例过滤阶段,我们引入了一个称为CLIP互相似度的指标。利用CLIP[21]图像编码器,我们提取生成数据和真实数据的嵌入,然后计算它们的相似度。较低的相似度表示较低的数据质量。过滤后,我们获得最终的生成数据集。在实例增强阶段,我们使用实例粘贴策略[34]来提高模型在生成数据上的学习效率。
\ 实验表明,我们设计的数据多样性策略可以有效提高模型性能,并在数据规模增加到百万级时保持性能提升的趋势,这使得大规模生成数据用于数据增强成为可能。在LVIS数据集上,DiverGen显著优于强大的模型X-Paste[34],在所有类别上实现了+1.1框AP[8]和+1.1掩码AP,在稀有类别上实现了+1.9框AP和+2.5掩码AP。
\ 总结而言,我们的主要贡献如下:
\ • 我们从分布差异的角度解释了生成数据的作用。我们发现生成数据可以扩展模型可以学习的数据分布,减轻对训练集的过拟合,而生成数据的多样性对提高模型性能至关重要。
\ • 我们提出了生成数据多样性增强策略,从类别多样性、提示多样性和生成模型多样性方面增加数据多样性。通过增强数据多样性,我们可以将数据规模扩展到数百万,同时保持模型性能提升的趋势。
\ • 我们优化了数据生成流程。我们提出了一种SAM-background标注策略,以获得更高质量的标注。我们还引入了一个称为CLIP互相似度的过滤指标,用于过滤数据并进一步提高生成数据集的质量。
2. 相关工作
实例分割。实例分割是计算机视觉领域的一项重要任务,已被广泛研究。与语义分割不同,实例分割不仅在像素级对像素进行分类,还区分同一类别的不同实例。以前,实例分割研究的重点主要是模型结构的设计。Mask-RCNN[9]统一了目标检测和实例分割任务。随后,Mask2Former[4]通过利用DETR[2]的结构,进一步统一了语义分割和实例分割任务。
\ 与这些专注于模型架构的研究正交,我们的工作主要研究如何更好地利用生成数据进行此任务。我们专注于具有挑战性的
\ 
\ 长尾数据集LVIS[8],因为只有长尾类别面临有限真实数据的问题,需要生成图像进行增强,这使其更具实际意义。
\ 生成数据增强。使用生成模型合成训练数据以辅助分类[6, 32]、检测[3, 34]、分割[14, 27, 28]等感知任务已受到研究人员的广泛关注。在分割领域,早期工作[13, 33]利用生成对抗网络(GANs)合成额外的训练样本。随着扩散模型的兴起,已有众多努力[14, 27, 28, 30, 34]利用文本到图像扩散模型(如Stable Diffusion[22])来提升分割性能。Li等人[14]将
您可能也会喜欢

流动性战争抹去数十亿:DWF Labs的Andrei Grachev敲响警钟

Uniswap鲸鱼在"UNIfication"上涨44%时抛售价值7500万美元的UNI – 内部人士退出还是巧合?
