

دراسة الاستئصال تؤكد ضرورة المعدلات الديناميكية لأداء RECKONING
جدول الروابط
نبذة مختصرة و1. المقدمة
-
الخلفية
-
الطريقة
-
التجارب
4.1 أداء الاستدلال متعدد الخطوات
4.2 الاستدلال مع المشتتات
4.3 التعميم على المعرفة الواقعية
4.4 تحليل وقت التشغيل
4.5 حفظ المعرفة
-
الأعمال ذات الصلة
-
الخاتمة، وشكر وتقدير، والمراجع
\ أ. مجموعة البيانات
ب. الاستدلال في السياق مع المشتتات
ج. تفاصيل التنفيذ
د. معدل التعلم التكيفي
هـ. تجارب مع نماذج اللغة الكبيرة
د معدل التعلم التكيفي
تظهر الأعمال السابقة [3، 4] أن معدل التعلم الثابت المشترك عبر الخطوات والمعلمات لا يفيد أداء التعميم للنظام. بدلاً من ذلك، يوصي [3] بتعلم معدل تعلم لـ
\ 
\ 
\ كل طبقة شبكة وكل خطوة تكيف في الحلقة الداخلية. يمكن لمعلمات الطبقة أن تتعلم ضبط معدلات التعلم ديناميكيًا في كل خطوة. للتحكم في معدل التعلم α في الحلقة الداخلية بشكل تكيفي، نحدد α كمجموعة من المتغيرات القابلة للتعديل: α = {α0, α1, …αL}، حيث L هو عدد الطبقات ولكل l = 0, …, L، αl هو متجه بـ N عنصر نظرًا لعدد خطوات الحلقة الداخلية المحدد مسبقًا N. تصبح معادلة تحديث الحلقة الداخلية إذن
\ 
\ 
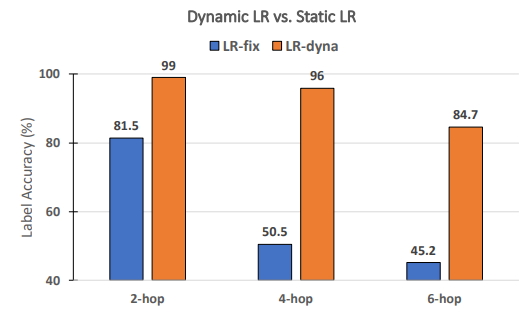
\ هل معدلات التعلم الديناميكية ضرورية لأداء RECKONING؟ بناءً على الأعمال السابقة في التعلم الفوقي [3، 4]، نتعلم ديناميكيًا مجموعة من معدلات التعلم لكل خطوة ولكل طبقة لـ RECKONING. في هذه الدراسة الاستئصالية، نحلل ما إذا كانت معدلات التعلم الديناميكية للحلقة الداخلية تحسن بشكل فعال أداء الاستدلال في الحلقة الخارجية. وبالمثل، نثبت الإعدادات التجريبية الأخرى ونحدد عدد خطوات الحلقة الداخلية إلى 4. كما يوضح الشكل 8، عند استخدام معدل تعلم ثابت (أي تشترك جميع الطبقات وخطوات الحلقة الداخلية في معدل تعلم ثابت)، ينخفض الأداء بهامش كبير (متوسط انخفاض 34.2٪). يصبح انخفاض الأداء أكثر أهمية في الأسئلة التي تتطلب المزيد من خطوات الاستدلال (انخفاض بنسبة 45.5٪ للخطوات الأربع و39.5٪ للخطوات الست)، مما يوضح أهمية استخدام معدل تعلم ديناميكي في الحلقة الداخلية لإطار عملنا.
\ 
\
:::info المؤلفون:
(1) زيمينغ تشن، EPFL (zeming.chen@epfl.ch)؛
(2) غيل وايس، EPFL (antoine.bosselut@epfl.ch)؛
(3) إريك ميتشل، جامعة ستانفورد (eric.mitchell@cs.stanford.edu)'؛
(4) أسلي سيليكيلماز، Meta AI Research (aslic@meta.com)؛
(5) أنطوان بوسيلوت، EPFL (antoine.bosselut@epfl.ch).
:::
:::info هذه الورقة متاحة على arxiv تحت ترخيص CC BY 4.0 DEED.
:::
\
قد يعجبك أيضاً

سهم شركة سولانا (HSDT): يرتفع مع وصول حيازات SOL إلى 2.3 مليون بأداء عائد 7%

تيراوولف تقترح عرضاً خاصاً بقيمة 500 مليون دولار من سندات كبار المستثمرين القابلة للتحويل لتمويل مشروع الذكاء الاصطناعي المدعوم من جوجل
