

Solucionando el mayor obstáculo de la segmentación 3D
:::info Autores:
(1) George Tang, Instituto Tecnológico de Massachusetts;
(2) Krishna Murthy Jatavallabhula, Instituto Tecnológico de Massachusetts;
(3) Antonio Torralba, Instituto Tecnológico de Massachusetts.
:::
Tabla de Enlaces
Resumen y I. Introducción
II. Antecedentes
III. Método
IV. Experimentos
V. Conclusión y Referencias
\ 
\ Resumen— Abordamos el problema de aprender una representación implícita de escena para segmentación de instancias 3D a partir de una secuencia de imágenes RGB con pose. Para ello, presentamos 3DIML, un marco novedoso que aprende eficientemente un campo de etiquetas que puede renderizarse desde nuevos puntos de vista para producir máscaras de segmentación de instancias consistentes. 3DIML mejora significativamente los tiempos de entrenamiento e inferencia de los métodos existentes basados en representación implícita de escenas. A diferencia de técnicas anteriores que optimizan un campo neuronal de manera autosupervisada, requiriendo procedimientos de entrenamiento complicados y diseño de funciones de pérdida, 3DIML aprovecha un proceso de dos fases. La primera fase, InstanceMap, toma como entrada máscaras de segmentación 2D de la secuencia de imágenes generadas por un modelo de segmentación de instancias frontend, y asocia las máscaras correspondientes a través de imágenes a etiquetas 3D. Estas máscaras de pseudoetiquetas casi consistentes se utilizan luego en la segunda fase, InstanceLift, para supervisar el entrenamiento de un campo de etiquetas neuronal, que interpola regiones omitidas por InstanceMap y resuelve ambigüedades. Además, introducimos InstanceLoc, que permite la localización en tiempo casi real de máscaras de instancias dado un campo de etiquetas entrenado y un modelo de segmentación de imágenes prefabricado, fusionando las salidas de ambos. Evaluamos 3DIML en secuencias de los conjuntos de datos Replica y ScanNet y demostramos la efectividad de 3DIML bajo supuestos leves para las secuencias de imágenes. Logramos una gran aceleración práctica sobre los métodos existentes de representación implícita de escenas con calidad comparable, mostrando su potencial para facilitar una comprensión de escenas 3D más rápida y efectiva.
I. INTRODUCCIÓN
Los agentes inteligentes requieren comprensión de escenas a nivel de objeto para llevar a cabo eficazmente acciones específicas del contexto como navegación y manipulación. Si bien la segmentación de objetos en imágenes ha visto un progreso notable con modelos escalables entrenados en conjuntos de datos a escala de internet [1], [2], extender tales capacidades al entorno 3D sigue siendo un desafío.
\ En este trabajo, abordamos el problema de aprender una representación de escena 3D a partir de imágenes 2D con pose que factoriza la escena subyacente en su conjunto de objetos constituyentes. Los enfoques existentes para abordar este problema se han centrado en entrenar modelos de segmentación 3D agnósticos a la clase [3], [4], requiriendo grandes cantidades de datos 3D anotados y operando directamente sobre representaciones explícitas de escenas 3D (por ejemplo, nubes de puntos). Una clase alternativa de enfoques [5], [6] ha propuesto en cambio elevar directamente máscaras de segmentación desde modelos de segmentación de instancias prefabricados a representaciones 3D implícitas, como campos de radiancia neuronal (NeRF) [7], permitiéndoles renderizar máscaras de instancias consistentes en 3D desde nuevos puntos de vista.
\ Sin embargo, los enfoques basados en campos neuronales han seguido siendo notoriamente difíciles de optimizar, con [5] y [6] tomando varias horas para optimizar imágenes de resolución baja a media (por ejemplo, 300 × 640). En particular, Panoptic Lifting [5] escala cúbicamente con el número de objetos en la escena, impidiendo que se aplique a escenas con cientos de objetos, mientras que Contrastively Lifting [6] requiere un procedimiento de entrenamiento complicado de múltiples etapas, obstaculizando la practicidad para su uso en aplicaciones robóticas.
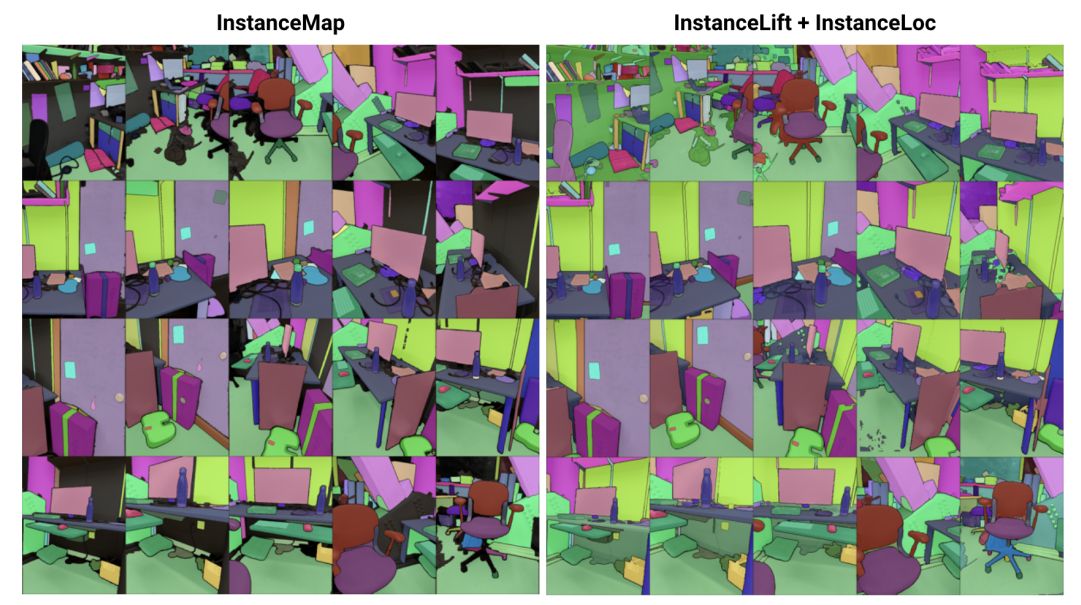
\ Para este fin, proponemos 3DIML, una técnica eficiente para aprender segmentación de instancias consistente en 3D a partir de imágenes RGB con pose. 3DIML comprende dos fases: InstanceMap e InstanceLift. Dadas máscaras de instancia 2D inconsistentes extraídas de la secuencia RGB utilizando un modelo de segmentación de instancias frontend [2], InstanceMap produce una secuencia de máscaras de instancia consistentes. Para hacerlo, primero asociamos máscaras entre frames utilizando coincidencias de puntos clave entre pares de imágenes similares. Luego usamos estas asociaciones potencialmente ruidosas para supervisar un campo de etiquetas neuronal, InstanceLift, que aprovecha la estructura 3D para interpolar etiquetas faltantes y resolver ambigüedades. A diferencia de trabajos anteriores, que requieren entrenamiento en múltiples etapas e ingeniería adicional de funciones de pérdida, utilizamos una única pérdida de renderizado para la supervisión de etiquetas de instancia, permitiendo que el proceso de entrenamiento converja significativamente más rápido. El tiempo de ejecución total de 3DIML, incluido InstanceMap, toma 10-20 minutos, en comparación con 3-6 horas para técnicas anteriores.
\ Además, diseñamos InstaLoc, un pipeline de localización rápido que toma una vista nueva y localiza todas las instancias segmentadas en esa imagen (utilizando un modelo de segmentación de instancias rápido [8]) mediante consultas dispersas al campo de etiquetas y fusionando las predicciones de etiquetas con regiones de imagen extraídas. Finalmente, 3DIML es extremadamente modular, y podemos intercambiar fácilmente componentes de nuestro método por otros más eficientes a medida que estén disponibles.
\ Para resumir, nuestras contribuciones son:
\ • Un enfoque eficiente de aprendizaje de campo neuronal que factoriza una escena 3D en sus objetos constituyentes
\ • Un algoritmo rápido de localización de instancias que fusiona consultas dispersas al campo de etiquetas entrenado con modelos de segmentación de instancias de imágenes eficientes para generar máscaras de segmentación de instancias consistentes en 3D
\ • Una mejora general del tiempo de ejecución práctico de 14-24× sobre técnicas anteriores evaluadas en una sola GPU (NVIDIA RTX 3090)
II. ANTECEDENTES
Segmentación 2D: La prevalencia de la arquitectura de transformadores de visión y la creciente escala de conjuntos de datos de imágenes han resultado en una serie de modelos de segmentación de imágenes de última generación. Panoptic y Contrastive Lifting elevan máscaras de segmentación panóptica producidas por Mask2Former [1] a 3D aprendiendo un campo neuronal. Hacia la segmentación de conjunto abierto, segment anything (SAM) [2] logra un rendimiento sin precedentes al entrenar con mil millones de máscaras en 11 millones de imágenes. HQ-SAM [9] mejora SAM para máscaras de grano fino. FastSAM [8] destila SAM en una arquitectura CNN y logra un rendimiento similar siendo órdenes de magnitud más rápido. En este trabajo, utilizamos GroundedSAM [10], [11], que refina SAM para producir segmentación a nivel de objeto, en lugar de a nivel de parte.
\ Campos neuronales para segmentación de instancias 3D: Los NeRFs son representaciones implícitas de escenas que pueden codificar con precisión geometría compleja, semántica y otras modalidades, así como resolver supervisión inconsistente desde diferentes puntos de vista [12]. Panoptic lifting [5] construye ramas semánticas y de instancias sobre una variante eficiente de NeRF, TensoRF [13], utilizando una función de pérdida de emparejamiento húngaro para asignar máscaras de instancia aprendidas a IDs de objetos sustitutos dadas máscaras de referencia inconsistentes. Esto escala pobremente con el aumento del número de objetos (debido a la complejidad cúbica del emparejamiento húngaro). Contrastive lifting [6] aborda esto empleando en su lugar aprendizaje contrastivo en características de escena, con relaciones positivas y negativas determinadas por si se proyectan o no en la misma máscara. Además, contrastive lifting requiere una pérdida basada en agrupamiento lento-rápido para un entrenamiento estable, lo que lleva a un rendimiento más rápido que panoptic lifting pero requiere múltiples etapas de entrenamiento, llevando a una convergencia lenta. Concurrentemente a nosotros, Instance-NeRF [14] aprende directamente un campo de etiquetas, pero basan su asociación de máscaras en la utilización de NeRF-RPN [15] para detectar objetos en un NeRF. Nuestro enfoque, por el contrario, permite escalar a resoluciones de imagen muy altas mientras requiere solo un pequeño número (40-60) de consultas de campo neuronal para renderizar máscaras de segmentación.
\ Structure from Motion: Durante la asociación de máscaras en InstanceMap, nos inspiramos en pipelines escalables de reconstrucción 3D como hLoc [16], incluido el uso de descriptores visuales para emparejar primero puntos de vista de imágenes, luego aplicando emparejamiento de puntos clave como preliminar para la asociación de máscaras. Utilizamos LoFTR [17] para la extracción y emparejamiento de puntos clave.
\
:::info Este artículo está disponible en arxiv bajo la licencia CC by 4.0 Deed (Atribución 4.0 Internacional).
:::
\
También te puede interesar

La cartera de Telegram ahora ofrece rendimiento DeFi en USDT con Affluent

El avance cuántico de Google hace que la amenaza a Bitcoin sea 'más real', dicen los científicos
